|
|
|
|
|

FEATURE
The ‘Long Tale’: Using Web 2.0 Concepts to Enhance Digital Collections
by Andrew Bullen
The wonderful Web 2.0 is a famously slippery concept to define. The very ambiguity of the term is Escheresque, self-referential to its ever-changing meaning. As Tim O’Reilly, CEO of O’Reilly Media, described it, “Like many important concepts, Web 2.0 doesn’t have a hard boundary, but rather, a gravitational core.” As Illinois State Library’s information technology coordinator, I have come to realize that embracing this essential Web 2.0 philosophy is a useful tool in unlocking the true potential of digital collections. In fact, the central premise behind this article is that until we embrace Web 2.0 concepts, digital repositories cannot evolve beyond very useful cataloging tools.
All digital collection and information repository tools excel at collecting and disseminating information about the individual items described in their database systems. However, most lack a coherent mechanism for placing the items in context. Images and objects appear one after another in artificial order, devoid of any descriptive connection to each other or to their historical context.
As professionals, we have embraced the concept of preserving materials as digital objects, defined a wide-ranging series of increasingly sophisticated cataloging (metadata) systems, and developed quality assurance and trusted repository programs. In my very humble opinion, however, we have yet to embrace the next logical step, which is to provide context for the images in our collections. Our image repositories are grouped together with as much relevance as posters in a display at a neighborhood head shop; except for an overarching collection theme, our digital objects exist in splendid isolation, beautifully cataloged but bereft of supporting and defining context.
My interpretation of Web 2.0 is that it is a blurring of boundaries. This is the powerful philosophy that will guide the three parts of this article: joining existing tools to put digital images in context, creating tangential or related stories (which I have taken to referring to as the “long tale”), and enabling audience participation to enrich your content.
Putting an Image in Context
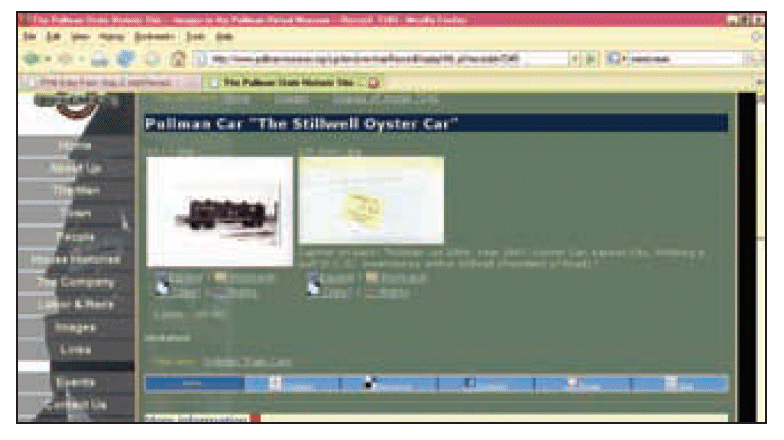
No digital object exists as an atomic fact by itself. It exists in a deterministic universe, resulting from a past and describing a contemporary event. Consider Figure 1 as an example:
This image is part of the Arthur Dubin collection at Lake Forest College. The college has very generously allowed the Pullman State Historic Site to display about 100 unique railroad images from Dubin’s collection. As cataloged in our image repository system, the record for this image describes the image adequately, identifying the car as “The Stillwell [sic] Oyster Car” and quoting the caption found on the back (see Figure 2).
(This is a homegrown, LAMP-based system.) As it turns out, the story behind this car, and particularly its inventor, is a fascinating one. Arthur E. Stilwell developed this revolutionary car in 1894; his invention met a need for fresh fish and oysters, popular items in 19th-century diets. Stilwell was an eccentric genius and railroad builder. In the space of just 7 years, he went from pauper to millionaire, built 3,000 miles of railroad tracks, and founded 40 towns. He credited his remarkable success to the voices in his head. Stilwell was a poor money manager, however, and was in and out of debt his entire life. On the day of George Pullman’s death in 1897, he was to have met with Stilwell; Stilwell hoped that Pullman would finance yet another one of his schemes. When he died on Sept. 26, 1928, Stilwell’s estate was worth only $1,000. Among other towns, Stilwell founded Port Arthur, Texas, home to Janis Joplin.
No part of this endlessly fascinating story can be found anywhere in this record. Furthermore, in our digital repository the default browser view of this record arranges it between a record of a 1916 steam engine and an inventory of another Pullman collection in our digital repository. Context can be derived neither from its position nor from its metadata.
My solution to this context-image disconnect is to use different software tools to do what they do best and combine them through other, largely homegrown, software tools. Digital repositories are excellent at cataloging digital objects. Content management systems (CMSs) are excellent at managing comprehensive textual entries. For our Pullman site (www.pullman-museum.org), we are working on combining the two through Perl and PHP programs that read in data from digital repositories and “inject” it into the appropriate content management system record. We are using WordPress as our CMS, and we have a homegrown digital repository. The most relevant or interesting digital objects in the collection are dynamically placed in the sidebar, along with a descriptive title and link to the full record. My small PHP program does this by finding the main subject of the page and doing a SQL query on the database for image records that have the same subject and then arranging them in the appropriate manner. Since there might be many, many records that share the same subject, we have selected the best, most exemplary images and designated them as such in a database field (mainSubjectOf), which can then be selected.
Of course, this is homegrown software; I can tweak it and modify it at will. Let us examine how to take two off-the-shelf products and join them together. For this example, I will use OCLC’s ContentDM as a digital repository and WordPress as a CMS. ContentDM does not use a relational database as its back end, so we will need to transfer a subset of the data into a database table. (I am reluctant to work with OCLC’s data structures directly; I would prefer to touch them as lightly as I can.) Our first step is to then insert the data into our table, held conveniently in a nice XML file called desc.all. The simple (ActiveState) Perl program that I use to read in the data can be seen here:
|
open (WOMBAT, “d:\\pshs\\index\\description\\desc.all”);
open (RESULTS, “>d:\\pshs\\index\\description\\parseResults.txt”);
$i=0; $line=““;
while (<WOMBAT>) {
$i++;
if ($i==1) {
$title = $_;
$title = substr ($title, 7, index ($title, “</title>“) - 7);
}
if ($i==2) {
$subject = $_;
$subject = substr ($subject, 8, index ($subject, “</subjec>“) - 8);
}
if ($i==19) {
$image = $_;
$image = substr ($image, 6, index ($image, “</find>“) - 6);
}
if ($i==23) {
$uid = $_;
$uid = substr ($uid, 10, index ($uid, “</dmrecord>“) - 10);
$i=0;
print RESULTS $title . “|” . $subject . “|” . $image . “|” . $uid .”\n”;
}
}
close WOMBAT; close RESULTS;
Here is an example of our target record, from desc.all:
<title>Pullman Family at Summer location</title>
<subjec>Pullman Family</subjec>
<descri>Extended family, possibly at Fairlawn, one of their summer homes. George has his four children arround him, and possibly his mother or someone else, as she does not look like Hattie. Ca mid 1890’s</descri>
<creato></creato>
<publis>Pullman State Historic Site</publis>
<contri></contri>
<date>Unknown; 2007-02-01</date>
<type>Photograph (all forms)</type>
<format>HP Scanjet 4470C; 300 DPI; 24 Bit; TIFF; No Compression</format>
<identi>2092; http://www.pullman-museum.org/cgi-bin/pvm/main
RecordDisplayXML.pl?recordid=10988; prg12</identi>
<source></source>
<langua>EN-English</langua>
<relati></relati>
<covera></covera>
<rights>The Industrial Heritage Archives provides reproductions of items from its collections for personal or research use. If an image is to be reproduced in any type of publication or on the web, written permission is required and use fees may be assessed. Us</rights>
<audien></audien>
<dmaccess></dmaccess>
<dmoclcno></dmoclcno>
<find>363.jpg</find>
<fullrs></fullrs>
<dmcreated>2007-09-28</dmcreated>
<dmmodified>2007-09-28</dmmodified>
<dmrecord>293</dmrecord>
I use this program to read through the data in desc.all and write it into a character delimited file (delimited by the pipe | symbol). I can then insert this data into a MySQL table. In the appropriate WordPress theme file (single.php), I slip in a line of code that calls yet another program:
<?php include (“wp-test.php”); ?>
The program it calls (wp-test.php) looks up records that match the desired subject (see page 34).
<?php
$query=“SELECT * FROM contentDM where subject like \”$the_category%\” ORDER BY title”;
$result=mysql_query($query);
$num = mysql_num_rows ($result);
mysql_close();
if ($num > 0 ) {
$i=0;
while ($i < $num) {
$title = mysql_result
($result,$i,”title”);
$subject = mysql_result
($result,$i,”subject”);
$image = mysql_result
($result,$i,”imageID”);
$dmRecord = mysql_result
($result,$i,”uid”);
$image = “icon” . $image;
$image = “<img src=\”
http://www.idaillinois.org/pshs/image/”
. $image . “\”>“;
$dmRecord = “<em><a href=\”http://www.idaillinois.org/u?/pshs,” . $dmRecord . “\”>More...</a></em>\n”;
echo “<span style=\”font-face: arial; color: #aa0000; font-size: 8pt;\”>$image<br />$title<br />$dmRecord</span><p />“;
++$i;
}
}
else { echo “No images match your query...”; }?>
echo “<span style=\”font-face: arial; color: #aa0000; font-size: 8pt;\”>$image<br />$title<br />$dmRecord</span><p />“;
The line actually writes out the data. If we choose, we could write this out into a table format as I have done in my previous example. This concept works equally well as a stand-alone program, used with static HTML pages as a server-side include.
|
|
Using our ContentDM installation as our digital repository and WordPress as our CMS, we can map out a simple workflow:
1. Add repeating fields to ContentDM as mainSubjectOf, populating the best or most relevant examples in the collection with appropriate subject selections.
2. Build a MySQL table with data fields parsed from your ContentDM collection.
3. Add subjects that exactly match the subjects in mainSubjectOf to the appropriate WordPress entries.
4. Modify my simple wp-test.php program as needed, and insert it as an include statement in an appropriate theme PHP program.
5. Build a small program that determines the date of the ContentDM collection file; if it has been updated, reread in the file and update or insert the information into the table as appropriate.
Creating the ‘Long Tale’
Some images are worth a thousand words: See Figure 3. This is an image of the Pullman family, almost certainly taken at Fairlawn, George Pullman’s estate in Elberon, N.J. Although we cannot be certain, it was probably taken during the famous 1894 Pullman strike; he spent much of the strike encamped in New Jersey. Surrounding George Pullman (the goateed man standing on the right) are his immediate family (excepting his wife) consisting of his two daughters, Florence and Hattie, and his twin sons, [Walter] Sanger and George Jr.
This image is a good example of something I call a “nodal image,” in that it can point to so many other references. Consider this: From this image, we can discuss Elberon, N.J., once the playground of the rich and famous in the 19th century. President Garfield was brought to Elberon after being shot and wounded by Charles Gutieau, his physicians hoping that the pleasant atmosphere would aid his recovery. We can also discuss the dissolute lives of the Pullman twins, who were archetypal spoiled, rich, ne’er-do-well hell-raisers. (George Pullman Jr., for instance, had a very torrid and public affair with Blanche Bowers, wife of then-famous composer and producer Frederick Bowers.) I call this great chain of linkages the “long tale,” a design concept that allows digital repositories to explore all of the connections between narratives and images. The long tale takes a discrete object and expands out its connections. Using the long tale design philosophy creates a digital collection that evolves into an ever-denser collection of digital objects and narrative description, becoming (if I may borrow a Hindu concept) a net of jewels.
Software exists that does allow the linkage of such disparate stories into an ever-growing net of information—wiki software. I have come to believe that digital repository tools acting in concert with wiki software (I use MediaWiki) can be the backbone of my long tale ideal. Figure 4 shows a MediaWiki page on our entrepreneur Arthur Stilwell.
I have added a link to each of my (again, homegrown) image record display screens that allow a user to promote an image to nodal status. The Perl module MediaWiki.pm creates a new page or allows a user to log into an existing page, populated with an icon of the digital image and descriptive metadata fields. The user can then create a narrative through the MediaWiki editing interface.
Harnessing Collective Intelligence: Many Hands Make Light the Work
No cultural institution, to my knowledge, has anything even approaching limitless resources. Developing a long tale site requires a great deal of time and effort. The existing sites that do combine detailed explanation and images focus on high-value collections, such as the beautiful sites at the Bavarian State Library (www.digital-collections.de/index.html?c=sammlungen&1=en), The British Library (www.bl.uk/onlinegallery/homepage.html), and the Olympic Peninsula Community Museum (http://content.lib.washington.edu/cmpweb). Such an approach—curated, high-value, and labor-intensive—cannot be easily accomplished except by a small number of technologically sophisticated and experienced institutions. Most cultural institutions cannot rely on these kinds of resources. It is therefore imperative to expand out the site’s author and editor base to include the site’s audience. As an example, imagine the intellectual power that the Pullman site can potentially harness. There is a large audience that cares about Pullman—railroad buffs, labor historians, former residents, and so on. Each population brings some part of the narrative to share. For instance, I personally have no particular interest in the details of passenger car service; however, there are whole societies of people who do care passionately about the subject. Imagine what they can contribute, particularly with the railroad images of the Dubin collection from Lake Forest College.
Not all collections and subjects can boast of such a large and knowledgeable audience. Collections without a ready base of dedicated contributors can, using the long tale philosophy, reach beyond consumers across the internet itself to recruit producers. This is not a new concept, of course, but it is proven to be an effective one. To cite one example, the beautifully executed collection called Urban Landscapes from the Field Museum (www.idaillinois.org/cdm4/browse.php?CISOROOT=%2Ffmnh2), from the Field Museum of Natural History here in Chicago, has engaged its audiences in helping to expand its image information through a CGI form, accessible through a link on each ContentDM record.
I have advocated using the audience as co-producers, but a long tale collection should also allow users to be consumers. Each image at the Pullman site can be sent as a postcard to an email address using Postcard Direct code. Users share the tangible benefits of the online collection in a very real sense. Unexpectedly, the images have functioned as a sales catalog as well, prompting users who want higher resolution scans to purchase them from the library. We have dutifully provided each image with a link to our fee schedule and our rights and reproductions information. A long tale site—a combination of narrative and image—will produce demand for copies of the images as the narrative gives depth to the image and vice versa.
In Conclusion
I firmly believe that the next step for object repositories lies in a melding of wiki and digital repository concepts. This as-yet undeveloped software package would allow the creation of metadata pertinent to the described object and allow the descriptions about each object to be expanded and interlinked by registered users. Existing object repository software does not even begin to allow the development of long tale descriptions, while current wiki software allows too much freedom and provides too little structure. Perhaps the MediaWiki software, being open source, can be heavily modified to incorporate the structures and data protection elements necessary.
I would also plead with granting agencies—the NEH, state agencies disbursing LSTA monies, IMLS, etc.—to fund projects specifically with the long tale philosophy in mind. Grant funds should be allocated to develop at least explanatory narratives about major segments of the project. Developing these narratives also can be a good opportunity to form lasting partnerships between cultural institutions.
We have any number of resources that we, as a profession, have digitized and made available online. I believe that our next step is to tie them together. |
Andrew Bullen is currently the information technology coordinator for the Illinois State Library and a resident of the Pullman neighborhood in Chicago. He can be reached at abullen@ameritech.net. |
|
|
|