FEATURE
A Dozen Primers on Standards
ARK
Acronym:
ARK
What it stands for:
Archival Resource Key
What is its purpose?
The ARK naming scheme is designed to facilitate the high-quality and persistent
identification of information objects. A founding principle of the ARK is that
persistence is purely a matter of service and is neither inherent in an object
nor conferred on it by a particular naming syntax. The best that an identifier
can do is to lead users to the services that support persistence. The term
ARK itself refers both to the scheme and to any single identifier that conforms
to it.
An ARK is a special kind of URL that connects users to three things: the
named object, its metadata, and the provider's promise about its persistence.
When entered into the location field of a Web browser, the ARK leads the user
to the named object. That same ARK, followed by a single question mark ('?'),
returns a brief metadata record that is both human- and machine-readable. When
the ARK is followed by dual question marks ('??'), the returned metadata contains
a commitment statement from the current provider.
Unlike the URN, DOI, and PURL schemes, the ARK scheme recognizes that two
important classes of name authority affect persistence: original assigners
of names and current providers of mapping services (which map names to objects,
to metadata, and to promises). Over time, the original assigner (the Name Assigning
Authority) and its policies increasingly have less to do with the current providers
(the Name Mapping Authorities) and their policies. There may be many mapping
authorities at once, and many in succession.
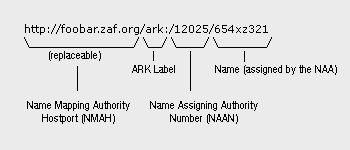
Here is an example illustrating the structure of an ARK:
The part of the ARK before the NAAN plays no part in identifying the object
or in comparing ARKs for equivalence; it only serves to make the ARK actionable.
The NMAH part is temporary, disposable, and replaceable. It is thus a kind
of identity-inert, disposable booster rocket that launches the ARK into cyberspace
while allowing for limited branding. When the Web no longer exists, the core
identity of the ARK is easily recovered by isolating the part of the ARK that
begins with "ark:/".
The following ARKs are synonyms for the same object:
http://foobar.zaf.org/ark:/12025/654xz321
http://sneezy.dopey.com/ark:/12025/654xz321
ark:/12025/654xz321
A carefully chosen hostname in the NMAH could last for decades. If the NMAH
ever fails, the ARK specification describes a look-up algorithm for finding
a new NMAH for the object. The algorithm is essentially a simplification of
the original URN resolver discovery algorithm that uses Domain Name System
(DNS) Naming Authority Pointer records. A simpler alternative look-up algorithm
is based on string-matching against a small, mirrored text file that functions
as a registry of NAANs; this is directly analogous to how old Internet host
tables were used for hostname lookup before DNS. The registry file is small
since it contains one entry per NAA. The Names assigned by those NAAs are tracked
in databases residing with the NAAs and NMAs.
Also, unlike the URN, DOI, and PURL schemes, the ARK scheme recognizes that
persistence is multidimensional, not just on or off. As found in the permanence
rating system (http://www.arl.org/newsltr/212/nlm.html) devised at the National
Library of Medicine and implemented at the National Agriculture Library, a
persistence promise is a faceted commitment statement. Since the future can
never be guaranteed, a promise made by a current provider with a good reputation
is the best you can do. To be credible, that promise should address such things
as how long an identifier will remain assigned to a given object, how long
that object will be accessible, and to what extent its content may be subject
to change.
Groups behind it:
Work on ARK started at the U.S. National Library of Medicine, Lister Hill
Center, Computer Science Branch (http://ark.nlm.nih.gov). Now the primary implementation
activity is at the California Digital Library (http://ark.cdlib.org). Some
experimentation is taking place at the World Intellectual Property Organization
(WIPO) and at the University of CaliforniaSan Diego.
Does it replace or update a previous standard?
No
What stage of development is it at?
The ARK specification is stable, but subject to ongoing refinement and extension.
Pros & Cons:
Pros: ARKs work with unmodified Web browsers. The buy-in cost
is low; you can use them for some of your objects or all of them. ARKs connect
you not only to objects, but also to their providers' metadata and commitment
statements. The existence of these three services can be quickly probed and
interpreted with very simple automated tools. ARKs fail gracefully, because
the core identity can be recovered by stripping off the hostname.
Cons: Tool support is immature.
—John A. Kunze
Preservation Technologies Architect
University of California, Office of the President
Oakland, Calif.
ARK Co-Developer
DOI
Acronym:
DOI
What it stands for:
Digital Object Identifier
What is its purpose?
The spec links customers with publishers/content suppliers, facilitating
digital rights management, supply chain management, and electronic commerce.
Most commonly, publishers employ the system to sell digital content—journal
articles, books, chapters of books, etc. Publishers can also use it to facilitate
linking to excerpts, as for promotional purposes.
The International DOI Foundation defines DOI as an entire system for "persistent
identification and interoperable exchange of intellectual property (IP) on
digital networks." In other words, DOI is used to identify ownership and track
the use of IP in cyberspace. DOI has been called "the bar code for intellectual
property." The system has three components: identifier, directory, and database.
The identifier has two parts—a prefix, which identifies the entity that
is registering the DOI, and a suffix, which identifies an individual item.
A pre-existing identifier (like an ISBN) can be part of the suffix.
The directory, which functions as an intermediary between the user and the
publisher, links DOI numbers with the servers on which the actual content is
held. A publisher may change servers or transfer ownership of the copyright
to another entity, but the DOI number will always remain linked to the content
itself.
The database, maintained by the publisher, contains information about the
materials and copyright holders. When a user clicks on a DOI link, he or she
is taken to the publisher's repository and either views the content directly
(if a subscription is in place) or perhaps sees a screen offering different
ways to purchase the content.
The "plumbing" underneath DOI is called Handle System technology (http://www.handle.net).
This is "a comprehensive system for assigning, managing, and resolving persistent
identifiers" ("handles") for Internet resources, which can also be used as
Uniform Resources Names (URNs). The Handle System, written in Java, can be
freely downloaded for research and educational purposes (http://www.handle.net/java_version.html).
For those who want to test drive the system, or those who prefer not to run
these services on their own, the Corporation for National
Research Initiatives (http://www.cnri.reston.va.us) operates a Public Local
Handle Service (http://hs9.cnri.reston.va.us/CNRIHS/index.html). CNRI operates
the DOI system and provides technical support as a contractor to the IDF.
Groups behind it:
International DOI Foundation (IDF) (http://www.doi.org)
The Association of American Publishers
(http://www.publishers.org), in conjunction with the Corporation for National
Research Initiatives (http://www.cnri.reston.va.us), originally developed
the system.
Registration of DOIs is accomplished via Registration Agencies (http://www.doi.org/registration_agencies.html),
which may specialize in certain types of IP. Registration fees are set by the
individual agencies. Once registered, a DOI can be used freely. The IDF itself
grants DOI prefixes freely to organizations wishing to use them for limited
research/education/experimentation projects (as opposed to commercial purposes).
Does it replace or update a previous standard?
DOI works with another standard. An OpenURL—a method for sending
metadata associated with a digital object—can contain a DOI as an attribute.
Embedding a DOI in an OpenURL can convey the correct copyright/licensing information
that allows a user to access the desired content.
What stage of development is it at?
In August 2003, the 10-millionth DOI was assigned via CrossRef (http://www.crossref.org),
which IDF identifies as "the first and still largest assigner of DOIs." This
is what the DOI for that article looks like:
DOI:10.1007/s00348-003-0647-4. Here is the Web link: http://dx.doi.org/10.1007/s00348-003-0647-4.
Pros & Cons:
Pros: DOI links look and work like standard hyperlinks, and
they can easily be cut and pasted. Also, DOI links are persistent. A DOI functions
as a standard machine-readable number, allowing for cross-system communication.
Once registered, DOIs can be used freely by anyone and are easily modified
without requiring re-registration. DOIs can incorporate existing ID information,
such as ISBNs, SKUs, etc. A publisher can add unique DOIs to different parts
of a resource—e.g., chapters in a book—so that a customer can easily
purchase only what is wanted or needed. An extensive list of benefits can be
found in the DOI Handbook (http://www.doi.org/handbook_2000/intro.html).
Cons: It costs money to affiliate with a registration agency
and register items. In addition, the spec is oriented toward publishers rather
than the library community. Furthermore, DOIs are not yet common in Web URLs;
the standard is obscure to most outside of the information professions. Some
feel the system is overly complex and wonder if publishers are capable of maintaining
DOI databases.
Additional comments:
The IDF offers a page of links (http://www.doi.org/demos.html) to some demos
of DOI in action. Content Directions, Inc., a DOI registration agency, also
offers some examples from its customers (http://doi.contentdirections.com/doi_examples.cgi).
Other references:
Automating the Digital Supply Chain: Just DOI It (2001)
http://www.contentdirections.com/
materials/SIIA-AutomatingSupplyChain.htm
Digital Object Identifiers: Not Just for Publishers (2002)
http://www.cmswatch.com/Features/
TopicWatch/FeaturedTopic/?feature_id=66
"DOI: A 2003 Progress Report" (D-Lib Magazine/June 2003)
http://www.dlib.org/dlib/june03/paskin/06paskin.html
What Is the Digital Object Identifier? (2003)
http://www.contentdirections.com/
materials/WhatistheDOI_files/frame.html
—Shirl Kennedy, Reference Librarian
MacDill Air Force Base, Tampa, Fla.
METS
Acronym:
METS
What it stands for:
Metadata Encoding & Transmission Standard
What is its purpose?
METS is intended to provide an XML-based language for encapsulating all descriptive,
administrative, and structural metadata needed for the retrieval, display,
management, and preservation of digital library objects. The Reference Model
for an Open Archival Information System (ISO 14721:2002) defines the sum of
metadata and data constituting a digital object as an "information package." It
also delineates three major forms of an information package:
1. A Submission Information Package (SIP), used to submit a digital
object to a repository system
2. An Archival Information Package (AIP), used to store a digital
object within a repository
3. A Dissemination Information Package (DIP), used to deliver a digital
object to an end user.
METS was designed to fulfill the role of SIP, AIP, and DIP for digital library
repository systems.
By trying to standardize the format that digital libraries might use to exchange
and store digital library objects, the METS initiative is trying to reduce
the overall cost to libraries of developing tools and systems to work with
digital library materials. If a single standard exists for the way a digital
library object should be composed, then software that's developed by one institution
to work with its local digital materials should be fairly easy to adopt at
another institution. The METS format is thus intended to form a stable base
for digital library development, which a variety of institutions can then collaboratively
build upon.
Groups behind it:
Digital Library Federation (METS Initiative Sponsor)
(http://www.diglib.org)
Library of Congress (METS Maintenance Agency)
(http://www.loc.gov/standards/mets)
Does it replace or update a previous standard?
No
What stage of development is it at?
Version 1.3 of the METS XML schema has been publicly released and endorsed
by the Digital Library Federation. It is already in production use at a variety
of institutions both within the United States and overseas. The METS Editorial
Board, which manages its further development, is preparing to submit METS to
NISO (National Information Standards Organization) as a NISO registration document.
Pros & Cons:
Pros: Given its flexibility and power, METS is a relatively
simple and straightforward tool for encoding digital library objects. It supports
a wide range of materials, including still images, text, audio, and video,
as well as mixtures of such formats.
Cons: Its flexibility in adapting to local practices can serve
as a mild barrier to interoperability between institutions. As an example,
METS will allow you to encode descriptive metadata however you want, but if
other institutions don't share your practices with regard to descriptive metadata,
it will be difficult for them to take advantage of your METS-based materials.
While the METS community is trying to facilitate the development of software
tools that can be freely shared among libraries, as well as trying to encourage
commercial software providers to support the standard, METS-based software
tools are still immature and require some XML expertise to employ.
—Jerome McDonough
Digital Library Development Team Leader
Elmer Bobst Library
New York University
New York, N.Y.
Chair of the METS Editorial Board
MODS
Acronym:
MODS
What it stands for:
Metadata Object Description Schema
What is its purpose?
MODS can carry the major data elements from a MARC record but does not use
the MARC tagging that one finds in the MARC XML schema. Instead, MODS represents
key bibliographic data with easily understood element names such as "title," "name," and "subject." This
makes it more friendly to communities that are not accustomed to the MARC numeric
tagging. MODS can be used to translate MARC records into XML, but it is also
suitable for creating original metadata records.
IT SERVES WELL AS A BRIDGE BETWEEN TRADITIONAL LIBRARY APPLICATIONS
AND BIBLIOGRAPHIC APPLICATIONS THAT DO NOT MAKE USE OF LIBRARY CATALOGING
OR METADATA FORMATS.
MODS was, in part, a response to the need to have a metadata format that
was not specific to the library community and the MARC standard, but that would
have a richer data element set than Dublin Core. MODS can function as a crossover
metadata format for XML applications that may make use of traditional library
cataloging data together with metadata with nontraditional origins. It retains
some key elements of the MARC record (such as the Leader values for Type of
Resource and Bibliographic level) that would allow someone to re-create a MARC
record from MODS, albeit with some loss of detail. It does not attempt to define
every data element that is found in the MARC record, but rather it has distilled
that record down to a selection of key elements that can serve a fairly wide
variety of metadata needs.
MODS will be modified as the MARC standard changes to maintain parallelism
with the MARC record so that translation from MARC to MODS will be possible.
It can also be modified in response to requests from the community that uses
MODS, at the discretion of the Library of Congress office that is shepherding
the MODS standard.
Group behind it:
Library of Congress, Network Development
and MARC Standards Office (http://www.loc.gov/standards/mods)
Discussion and Developers' listserv: mods@loc.gov
Does it replace or update a previous standard?
No, MODS exists in relation to, but does not replace, MARC XML. And it supports,
but is not identical to, MARC-encoded metadata.
What stage of development is it at?
MODS is now at version 3.0. The Library of Congress' intention is for version
3 to be a stable version that will encourage more use in production systems.
MODS is being used already in some digital library applications.
Pros & Cons:
Pros: If you can tolerate some uncertainty in your life, and
are developing a database or system that will contain metadata from a variety
of sources, including some library cataloging in MARC format, MODS is your
best choice of metadata formats. It serves well as a bridge between traditional
library applications and bibliographic applications that do not make use of
library cataloging or metadata formats.
Cons: If you are looking for a stable, widely used metadata
standard with time-tested implementation guidelines, then MODS is not for you.
MODS has the potential to develop in a number of different directions, depending
on the feedback of early adopters. You should consider it experimental in nature,
although maturing quickly.
—Karen Coyle
Digital Library Specialist
Berkeley, Calif.
NCIP
Acronym:
NCIP
What it stands for:
NISO Circulation Interchange Protocol
What is its purpose?
NCIP supports the open exchange of circulation information among the variety
of systems that libraries use today to support resource sharing. These systems
must exchange information about library users, items they wish to use, the
owners of the items, and the relationships among these three entities. For
example, in a consortial environment, a patron may place a hold on an item
that's in another library. The second library could check the item out to the
patron and ship it to him. The patron may return the item to his own library,
where it would be checked in and returned to the original library. NCIP could
support all of these interactions among disparate systems.
NCIP addresses the growing need for interoperability among disparate applications:
between self-service applications and circulation applications, between and
among various circulation applications, between circulation and interlibrary
loan applications, and between other related applications. NCIP allows for
three forms of activity between applications:
1. Look-up. Look-up services allow the initiating system to ask
the responding service for information about an agency (library or other service
provider), a user, or an item.
2. Update. Update services allow the initiating system to ask
the responding service to take actions: These include both asking the responding
system to create or change an object (record) and asking the responding system
to do a circulation transaction such as placing a hold or performing a checkout.
3. Notification. Notification services allow the initiating system
to inform the responding system that it has taken an action. Notification services
parallel the update services.
The protocol is implemented through profiles. Implementation profiles define
how the messages are exchanged and application profiles define the business
rules for implementing the protocol for a particular application.
The first implementation profile was developed at the same time as the protocol
itself. It encodes messages in XML UTF-8 for character encoding. Messages may
be exchanged using either HTTP/(S) or direct TCP/IP.
NISO Committee AT, the committee that drafted NCIP, also developed three
application profiles: one for self-service, one for Circulation-to-ILL Interchange,
and one for Direct Consortial Borrowing.
Groups behind it:
NCIP was approved by the NISO (http://www.niso.org) membership in 2002. The
Colorado State Library is the official maintenance agency for NCIP.
Does it replace or update a previous standard?
While NCIP doesn't actually replace a previous standard, it builds on experience
that people developed while using 3M SIP (Standard Interchange Protocol) and
SIP2 in self-service applications.
What stage of development is it at?
There is an active implementers group that meets regularly. NCIP is being
implemented by most major system providers and by organizations like OCLC.
Pros & Cons:
Pros: NCIP uses current technology that is relatively easy
to implement for system providers. It provides a rich set of messages, and
is supported by an active implementation support group.
Cons: Business rules for implementation are still evolving.
Additional comments:
Here are some references that will give you more information:
NCIP Implementation Group page, University of Chicago Library Staff Web:
http://www.lib.uchicago.edu/staffweb/groups/ncip
"The NISO Circulation Interchange Protocol: An overview and status report"
by Mark Needleman. (2000) Serials Review 26(4): 4245.
"The NISO Circulation Interchange Protocol (NCIP)—An XML Based
Standard," by Mark Needleman, John Bodfish, Tony O'Brien, James E. Rush, and
Pat Stevens.
Library Hi Tech (2001), Volume 19, Number 3: 223230. (DOI: 10.1108/0
7378830110405526) An abstract and a vehicle to purchase the full text are at
http://fernando.emeraldinsight.com/vl=6397120/cl=16/
fm=html/nw=1/rpsv/cw/mcb/07378831/v19n3/s3/p223.
"NISO Circulation Interchange Protocol (NISO Z39.83): a standard in trial"
by Pat Stevens. (2001), New Library World, 102(1162): 9399.
—Pat Stevens
Director, Cooperative Initiatives
OCLC Online Computer Library Center
Dublin, Ohio
Chair, NISO Standards Development Committee
Former Chair, NISO Committee AT
OAI-PMH Acronym:
OAI-PMH
What it stands for:
Open Archives Initiative Protocol for Metadata Harvesting
What is its purpose?
Narrowly, the OAI-PMH is a mechanism for harvesting XML-formatted metadata
from distributed collections of metadata. In a broader sense, it is a framework
for increasing interoperability that includes an architectural model, implementation
guidelines, a registry of implementers, and a common descriptive metadata format,
in addition to the harvesting protocol itself. An effort to include the expression
of rights information within the protocol is ongoing.
In the Open Archives Initiative (OAI) model, there are data providers and
service providers. Data providers (also called "repositories") make metadata
available for harvesting. Service providers harvest metadata from data providers,
and build value-added services on top of it, usually in the form of search-and-retrieval
services. Data providers and service providers communicate with each other
via the Protocol for Metadata Harvesting, a simple set of requests and responses
carried over HTTP.
For example, the request GetRecord is issued by the service provider
to retrieve a single metadata record from the data provider. GetRecord has
parameters for the key of the requested record and the metadata format desired
by the harvester. The appropriate response is to send the requested metadata
record in the requested format.
The OAI-PMH requires all repositories to support one metadata schema, oai_dc,
an XML representation of unqualified Dublin Core. That means that regardless
of the native metadata scheme or format used by the repository, it must be
able to convert its native metadata to oai_dc for harvesting. Other metadata
schemas can be used by agreement between data provider and service provider,
as long as the metadata is represented in XML. Libraries commonly use MODS
and MARCXML, two schemata for representing MARC21 semantics in XML.
Group behind it:
Open Archives Initiative (http://www.openarchives.org)
Does it replace or update a previous standard?
The current version of the protocol is 2.0, which supersedes versions 1.0
and 1.1. The OAI-PMH itself does not update or replace any previous standard.
However, the OAI-PMH spec is based on a protocol called "Dienst," developed
at Cornell University (http://www.cornell.edu).
What stage of development is it at?
OAI-PMH version 2.0 is stable and in production. Lists of registered data
providers and service providers are available on the OAI Web site.
Pros & Cons:
Pros: The OAI architecture somewhat resembles that of Internet
Search Engines, in that (meta)data from distributed sites is aggregated centrally
for search and retrieval. As such, it can be contrasted with protocols like
Z39.50, where searching is distributed, and only search results are aggregated
and processed centrally.
A major advantage of the OAI model over distributed search models is scalability.
Z39.50 tends to break down with more than a dozen targets, while hundreds of
sites can easily be aggregated under OAI. Separating the functions of data
provider and service provider lends simplicity and flexibility that encourages
innovation.
Cons: A disadvantage is that, at least when used with oai_dc,
all metadata is converted to a least-common-denominator format that may not
be optimal for certain purposes. Also, the aggregation of metadata from disparate
sites presents challenges in vocabulary control, presentation, and other areas.
Attribution of source presents an interesting challenge when metadata is harvested
into aggregations that are subsequently harvested by other service providers.
Additional comments:
People in the library community often find the OAI terminology confusing.
The initiative arose in the e-prints community, where the term "archive" is
used to mean an e-print server or repository of scholarly papers. "Open Archives" does
not refer to archives curated by archivists, and the OAI-PMH is available for
use by any institution with a store of metadata—whether it's an e-print
server, a library catalog, or a course management system.
A good tutorial on the OAI-PMH is available from the European Open Archives
Forum (http://www.oaforum.org/index.php).
—Priscilla Caplan
Assistant Director for Digital Library Services
Florida Center for Library Automation
Gainesville, Fla.
ONIX Acronym:
ONIX
What it stands for:
ONline Information eXchange
What is its purpose?
ONIX is a standard format that publishers use to distribute product information
to their trading partners, including wholesalers, retail and online booksellers,
book information services for booksellers and libraries, and other publishing-process
intermediaries.
As online bookselling became popular and all retailers wanted to provide
more information about books to their customers, publishers were beset by requests
to provide product information in many formats. Publishers were providing the
same information in 10 or more different formats, and they continually received
new requests for different formats. Requestors sometimes wanted slightly different
versions of the information, e.g., one wanted subtitles, another didn't; one
wanted the author's full name, another wanted just initials; etc.
There were also issues for the recipients of the information—the booksellers,
wholesalers, and reference services. They received data in wrong formats and
they were concerned about its accuracy.
In 1999, the American Association of Publishers (AAP) called a meeting of
publishers and their major trading partners to address these issues. The meeting
was extremely well-attended and all agreed that the publishing and bookselling
communities needed to work together to develop a standard for information exchange.
Thus, ONIX was born.
ONIX defines a list of fields that allows publishers to provide very rich
information about a book. In addition to basic data like ISBN, title, and author,
publishers can provide author biographies, book blurbs, reviews, pictures of
the book cover, etc. ONIX also defines the format for an "ONIX message," that
is, the exact format in which data are to be transmitted. An ONIX message is
a set of data elements defined by tags that is written in XML and that conforms
to a specific XML DTD (Document Type Definition). The DTD defines how to order
the data elements within the message and how to show relationships among the
elements. Because XML is easy to use, this makes ONIX a standard that both
large and small publishers can use.
Groups behind it:
ONIX was originally created by the American Association of Publishers (http://www.publishers.org).
Much of ONIX is based on the EPICS standard that was developed by EDItEUR
(http://www.editeur.org). EPICS, the EDItEUR Product Information Communication
Standard, is a much broader standard that was developed with the experience
of the U.S. Book Industry Study Group (http://www.bisg.org) and the U.K. Book
Industry Communication group (http://www.bic.org.uk). Very soon after beginning
the ONIX project, the AAP invited EDItEUR and BISG to join in the effort.
EDItEUR is now responsible for maintaining and promulgating the standard,
under the direction of the International ONIX Steering Committee, and in association
with BISG in the U.S. and BIC in the U.K.
The Book Industry Study Group represents U.S. publishers and their trading
partners to the International ONIX Committee. BISG is very active in ONIX's
maintenance. Home of the U.S. ONIX Committee, which recommends changes and
enhancements to the standard, BISG runs educational seminars on ONIX for publishers,
and is responsible for publicizing the standard in the U.S.
Does it replace or update a previous standard?
ONIX replaces the many formats that were in use between publishers and trading
partners before 2000. The most prominent of these were the formats requested
by Amazon, Bowker, and Ingram.
What stage of development is it at?
The AAP released ONIX 1.0 in January 2000. EDItEUR released ONIX 2.0, which
provided for a full XML implementation of the standard, in August 2001. The
latest release, Version 2.1, is available on the EDItEUR Web site, and was
unveiled in 2003.
Major online booksellers, wholesalers, and catalog publishers—such as
Amazon, Barnes & Noble, Ingram, and Bowker—are working with publishers
to make ONIX the standard for providing information about books.
Pros & Cons:
Pros: ONIX is important for the publishing community and for
consumers. Through ONIX, publishers and booksellers can provide complete and
accurate information about products to help people make informed purchasing
decisions.
Before ONIX's introduction, it was time-consuming and expensive for publishers
to exchange book information with their partners. ONIX increases efficiency
and decreases cost for all parties.
Cons: Using ONIX does require development and integration with
other systems for large publishers, book information providers, and booksellers.
Thus, while many feel that ONIX is important, and it is being used by many
companies, both publishers and information recipients have had to expend resources
on its implementation, and it will take some time for its use to become de
rigueur throughout the publishing community.
Additional comments:
Those of us who worked on creating the ONIX standard felt strongly that it
would benefit all of the publishing community and its customers. And the difference
between the quality and depth of information that consumers can find in online
bookselling services now compared to what it was 5 years ago surely shows that
to be true.
—Evelyn Sasmor
Sasmor Consulting, LLC
Princeton, N.J.
Former Chair, U.S. ONIX Committee
OpenURL
Acronym:
OpenURL
What it stands for:
Open Uniform Resource Locator
What is its purpose?
An OpenURL is a URL that links a citation to extended services that are independent
of the information provider where the citation originates. These extended services
may include an article's full text, biographical information about the author
of an article, a search in a library catalog for a journal or book represented
by the citation, a Web search, etc.
By far, the most popular use of OpenURLs is to link article citations in
an abstracting-and-indexing database to the full text of the articles at a
publisher or full-text aggregator Web site.
The structure of an OpenURL is composed of two parts: First, the base URL
is the service component or "resolver." This is typically the hostname of a
library-controlled server (or resolver) that processes the data in the rest
of the OpenURL. OpenURL resolvers depend on a knowledgebase of sources that
is used to find appropriate links for citations sent to the resolver. In most
cases, the knowledgebase contains electronic journals that a library subscribes
to and the URL syntaxes needed to directly link to articles within them.
Several library software vendors, including Ex Libris, Innovative Interfaces,
Endeavor Information Systems, and Serials Solutions, sell OpenURL resolvers.
Some libraries have designed and built OpenURL resolvers in-house.
The rest of the OpenURL is called the "descriptor," and consists of a defined
set of variables tacked on to the URL in HTTP GET method fashion. The descriptor
can contain the source of the OpenURL (e.g., the database that created the
OpenURL—OCLC FirstSearch, EBSCOhost, etc.), and metadata about
the article (or other information object) that the OpenURL describes. In the
case of a journal article, this would include the journal name, its ISSN, the
volume and issue numbers, the author's name, the title of the article, etc.
An example of an OpenURL follows:
Group behind it:
NISO Committee AX (http://library.caltech.edu/openurl)
Does it replace or update a previous standard?
No, it is a new standard.
What stage of development is it at?
It is currently a draft NISO standard and is in use by many information providers
and library software vendors. NISO Committee AX is currently pursuing its adoption
as a NISO standard.
Additional comments:
Most abstracting-and-indexing database providers are offering outbound OpenURL
links from their Web interfaces. These links are intended to point to a library's
local OpenURL resolver. Only a few such vendors (EBSCO, to name one) offer
the ability to link to a full-text article via an inbound OpenURL.
Many electronic journal providers require a Digital Object Identifier (DOI)
in order to link directly to the full text of a specific article. A nonprofit
organization called CrossRef (http://www.crossref.org) provides free DOI look-up
services. To link directly to the full text of an article at a publisher's
Web site, an OpenURL resolver might need to send the citation data out to CrossRef
via an OpenURL, receive a DOI back, and then link to the article at the publisher's
Web site with the DOI.
OpenURLs could eventually have applications outside the scholarly publishing
world. At some point, online book retailers might allow you to point OpenURLs
at their Web sites to check on the price and availability of a book, CD, or
DVD.
It's also easy to conceptualize OpenURL-like standards for entities other
than citations for articles or books. People, places, and consumer products
come to mind. For example, consumer products could have an "OpenURL" definition
that might include product name, vendor, year released, model number, etc.
If you were looking for a specific shoe by brand and size, your personal resolver
could check prices and availability at a number of online stores that were
compliant with the standard. Here are sites you might want to check:
OpenURL Committee's Web site: http://library.caltech.edu/openurl
The OpenURL Framework for Context-Sensitive Services: Standards Committee
AX; National Information Standards Organization (2003) http://www.niso.org/committees/committee_ax.html
OpenURL format specification: http://www.sfxit.com/OpenURL/openurl.html
SFX OpenURL Overview; Ex Libris (2003) http://www.sfxit.com/OpenURLStandards and Patents and the OpenURL; National Information Standards Organization
(2003) http://www.niso.org/committees/OpenURL/OpenURL-patent.html
—Mark Dahl
Library Technology Coordinator
Watzek Library
Lewis & Clark College
Portland, Ore.
RDF Acronym:
RDF
What it stands for:
Resource Description Framework
What is its purpose?
RDF is most commonly explained as a "framework" for describing resources
on the World Wide Web and, as such, can be characterized as metadata. An RDF
description may contain such information as a particular resource's authors,
creation date, organization, content, subject category or keywords, intended
audience, copyright and licensing information, and pretty much anything else
deemed significant. At its most basic level, it facilitates the interchange
of metadata.
We often hear RDF mentioned in conjunction with the so-called Semantic Web,
which Tim Berners-Lee described as "an extension of the current web in which
information is given well-defined meaning, better enabling computers and people
to work in cooperation." (See http://www.sciam.com/article.cfm?
articleID=00048144-10D2-1C70-84A9809EC588EF21.)
The Semantic Web has been defined as third-generation WWW. First-generation
Web content is basically hand-written HTML pages. Second-generation Web content
involves dynamically generated HTML pages, with content retrieved from a database
and inserted into a template or style sheet. Third-generation Web content will
be written in a rich mark-up language (such as XML), and it will employ metadata
schemes (such as RDF) to make that content both machine-readable and machine-processable.
According to the World Wide Web Consortium (W3C), "The Resource Description
Framework (RDF) integrates a variety of applications from library catalogs
and world-wide directories to syndication and aggregation of news, software,
and content to personal collections of music, photos, and events using XML
as an interchange syntax. The RDF specifications provide a lightweight ontology
system to support the exchange of knowledge on the Web." (See http://www.w3.org/RDF.)
In the W3C's Metadata Activity Statement (http://www.w3.org/Metadata/Activity),
a number of practical applications are suggested, among them: thesauri and
library classification schemes; Web sitemaps; describing the contents of Web
pages (e.g., Dublin Core—http://dublincore.org); describing the formal
structure of privacy practice descriptions (e.g., Platform for Privacy Preferences—http://www.w3.org/P3P);
describing device capabilities (e.g., Mobile Access Activity—http://www.w3.org/Mobile/Activity);
rating systems (e.g., PICS—http://www.w3.org/PICS); expressing metadata
about metadata; and digital signatures (http://www.w3.org/Signature/Activity).
Group behind it:
World Wide Web Consortium (W3C) (http://www.w3.org/RDF)
Does it replace or update a previous standard?
There is a sort of incestuous relationship among XML, RDF, and RSS. RSS 1.0
is actually RDF Site Summary 1.0; this version of the RSS standard "is a document
describing a 'channel' consisting of URL-retrievable items. Each item consists
of a title, link, and brief description. While items have traditionally been
news headlines (feeds), RSS has seen much repurposing in its short existence." (See
http://web.resource.org/rss/1.0/spec.) RDF/RSS documents are written in XML.
You will sometimes see an RSS 1.0 feed identified as RDF.
RDF has also been described as a sort of follow-on to PICS (http://www.w3.org/PICS),
an earlier specification facilitating the attachment of metadata to Internet
content.
What stage of development is it at?
According to Tim Bray—often called the father of XML—"RDF is well
into middle age as standards go, and it hasn't exactly turned the world inside
out. This despite fierce backing from Tim Berners-Lee, who sees RDF as a key
foundation component for the Semantic Web." (http://www.sciam.com/article.cfm?articleID=00048144-10D2-1C70-84A9809EC588EF21)
(See The RDF.net Challenge, below.)
Although some feel that it still shows promise, RDF has yet to attract widespread
adoption in the metadata community. On the other hand, the Dublin Core Metadata
Initiative (http://dublincore.org) has more or less picked up the RDF ball
and run with it. And the Open Directory, used by Google and other Web entities,
offers RDF "dumps" of its database (http://rdf.dmoz.org).
Pros & Cons:
Pros: Anything that facilitates the interchange of metadata
is a good thing. RDF is a flexible and extensible framework that could potentially
be used in a wide variety of applications. It facilitates interoperability
between Web-based applications involving the exchange of machine-readable information.
Cons: Some have described the syntax as clunky, and physically
ugly to look at. There is relatively limited tool support at this time, compared
to what is available for, say, plain vanilla XML. At least one XML guru feels
that the level of abstraction is so high that RDF is all but unusable by the
vast majority of developers. (See "RDF and other monkey wrenches" by Sean McGrath,
http://www.itworld.com/nl/ebiz_ent/03182003.)
Additional comments:
Dave Beckett's Resource Description Framework (RDF) Resource Guide http://www.ilrt.bris.ac.uk/discovery/rdf/resources
The RDF.net Challenge (2003) http://www.tbray.org/ongoing/When/200x/2003/05/21/RDFNet
The semantic web: How RDF will change learning technology standards http://www.cetis.ac.uk/content/20010927172953
The Semantic Web—on the respective Roles of XML and RDF (2000) http://www.ontoknowledge.org/oil/downl/IEEE00.pdf
What is RDF? (1998) http://www.xml.com/pub/a/2001/01/24/rdf.html
XML and the Resource Description Framework: The Great Web Hope https://www.infotoday.com/online/OL2000/medeiros9.html
—Shirl Kennedy
Reference Librarian
MacDill Air Force Base
Tampa, Fla.
RSS Acronym:
RSS
What it stands for:
While there isn't much debate in the RSS community as to what RSS stands
for, it has come to stand for two phrases: "Really Simple Syndication" and "Rich
Site Summary." It all depends on whom you talk to. I am partial to Really Simple
Syndication, in that it best describes RSS.
What is its purpose?
RSS has numerous purposes. First and foremost, it is the force behind allowing
content from possibly thousands of sites to be delivered in one place. Through
an aggregator—a piece of software that can be downloaded, like Newzcrawler
(http://www.newzcrawler.com), or used online, like Bloglines (http://www.bloglines.com)—users
can "subscribe" to the RSS feeds of many Web-based sources. The aggregator
will scan all of the subscribed RSS feeds (usually every hour) and the new
content will be delivered to the user. This eliminates the users' need to retrieve
content from those sites, instead automating the content delivery, and thereby
saving valuable time. It is essential to understand that RSS is pure content
and not other aspects of a Web page, such as a links list, an about page, or
even the banner.
Another use for RSS is the ability to place these feeds onto a Web page to
display current information. The concept is the same as above, but the method
of display differs. While it is more difficult to set up this type of display,
it can be a powerful addition to any site. An academic library specializing
in psychology, for example, can display the latest headlines from Moreover
(http://www.moreover.com) with the keyword "psychology." Tools now exist to
simplify this task for any novice. Examples include 2RSS (http://www.2rss.com) and Feedroll (http://www.feedroll.com).
While many have come to believe that RSS is only for content coming out of
the Weblog community, this is untrue. Many popular Web pages and news sources
provide RSS feeds for their content. For example, The New York Times (http://backend.userland.com/
directory/167/feeds/newYorkTimes),
Wired Magazine (http://www.wired.com/news/rss), CNET
(http://news.com.com/2009-1090-980549.html?tag=alias),
and many other online news sources provide this type of content.
RSS feeds have also bred their own search engines, such as Feedster,
which indexes the RSS feeds of thousands of resources and is more up-to-date
than most news engines. It accomplishes this by indexing the pure content of
the pages and not the other portions that sometimes clutter search engines.
Groups behind it:
For RSS creation, there is not one single claim, but many: Netscape (http://www.netscape.com) used it with the advent of "push" technology and its My Netscape system. Although
he has never claimed ownership of the spec, Dave Winer (http://www.scripting.com) claims to have co-invented RSS with Netscape before he started the popular
Weblog publishing/news aggregator software Userland (http://radio.userland.com).
The RSS 2.0 spec is now under development at the Berkman Center at Harvard
University (http://cyber.law.harvard.edu/home), where Winer is a fellow.
Following the transfer to Berkman, RSS 2.0 was licensed under Creative Commons
(http://creativecommons.org), where an advisory group has been formed to continue
its development.
Does it replace or update a previous standard?
RSS 2.0, the current version of the standard, replaced RSS 0.92 in June of
2003.
What stage of development is it at?
There has not been much further development since the 2.0 standard was transferred
to Berkman.
Pros & Cons:
Pros:
1. There are neither advertisements nor spam in RSS feeds.
2. RSS saves time. (For example, I have been able to cut down my reading
time from 4 hours to 30 minutes per day, while reading three times as much
content.)
3. RSS can be used to deliver content to your patrons and customers.
4. If you provide an RSS feed for your Web site, it is likely to boost
the number of people reading your content, enabling a higher return on investment.
5. Aggregators are inexpensive, and setup should require less than 10
minutes.
Cons:
1. Not every site has an RSS feed.
2. With ease of use comes the potential for information overload. Aggregators
can become unruly, quickly.
3. If you download one aggregator at work and one at home, it is difficult
to synchronize content between the two.
(This is why I believe that Web-based aggregators will be more popular in the
future.)
4. RSS content is not being used to its potential. While some feeds
can be customized now, more need to be available in the future.
—Steven M. Cohen
M.L.S./Webmaster/Librarian
Library Stuff (http://www.librarystuff.net)
Smithtown, N.Y.
SHIBBOLETH Acronym:
Shibboleth
What it stands for:
As defined by Webster's Revised Unabridged Dictionary (1913), "Shibboleth" is "the
criterion, test, or watchword of a party; a party cry or pet phrase." Visit
http://shibboleth.internet2.edu/why-shibboleth.html to learn more.
What is its purpose?
Shibboleth facilitates the sharing of Web-based, protected resources between
institutions. When a user at one institution tries to access a resource at
another, Shibboleth sends attributes about the user to the remote destination,
rather than making the user log in to that destination. Using the attributes,
the remote destination decides whether or not to grant access to the user.
Shibboleth preserves the user's privacy in three ways:
1. It releases only necessary information, which may not include the
user's identity.
2. It reduces or removes the requirement for content providers to
maintain accounts for users.
3. It allows access to controlled resources from anywhere in the world
as a trusted member of your home institution.
Groups behind it:
Internet2 (http://www.internet2.edu)
The Middleware Architecture Committee for Education (http://middleware.internet2.edu/MACE)
National Science Foundation and the NSF Middleware Initiative
(http://www.nsf-middleware.org)
IBM/Tivoli (http://www-3.ibm.com/software/tivoli)
Sun Microsystems (http://www.sun.com/index.xml)
RedIRIS (http://www.rediris.es/index.es.html)
Carnegie-Mellon University (http://www.cmu.edu)
Ohio State University (http://www.osu.edu/index.php)
Brown University (http://www.brown.edu)
Columbia University (http://www.columbia.edu)
Individual contributors
Internet2 member institutions
(http://www.internet2.edu/resources/Internet2MembersList.PDF).
Does it replace or update a previous standard?
Shibboleth implements the standards-based Shibboleth architecture, built
on top of OASIS' (http://www.oasis-open.org) Security Assertion Markup Language
(SAML) and a number of other directory and security standards.
What stage of development is it at?
Shibboleth version 1.1 was released in August 2003 and has been implemented
by more than 30 universities, content providers, and many international partners.
Shibboleth 2.0 is in design, and will include a large number of extensions
and new features.
Pros & Cons:
Pros: Shibboleth is extremely easy to deploy, in many instances
taking less than half a day's work.
Shibboleth provides a powerful, flexible attribute transport system that
easily integrates with a wide variety of legacy systems.
Also, Shibboleth protects the privacy of its users while simultaneously protecting
the business logic of the content provider.
Based on lightweight, extensible federations, Shibboleth can provide trusted
interoperability to heterogeneous communities.
In addition, Shibboleth is open-source and has a large support community
around it.
Cons: Shibboleth currently only works with Web applications,
and only supports SAML's POST profile.
Furthermore, no authentication system is bundled with Shibboleth, although
it requires one to function as an origin.
Existing campus infrastructure must be fairly well-developed—preferably
including an enterprise directory and a single sign-on solution—to get
the most from Shibboleth.
Additional comments:
For more information on Shibboleth or the Internet2 Middleware Initiative,
visit http://shibboleth.internet2.edu and http://middleware.internet2.edu.
There are other helpful documents as well:
Example Shibboleth Uses—Internet2 Middleware; Internet2 (2003) http://shibboleth.internet2.edu/shib-uses.html
Internet2 Document Library—Shibboleth Architecture; Internet2 (2002)
http://docs.internet2.edu/doclib/draft-internet2-mace-shibboleth-architecture-05.html
Internet2 Shibboleth Developers E-Mail List: http://mail.internet2.edu/wws/info/shibboleth-dev
Internet2 Shibboleth Web Authentication Project; Instructional Media and
Magic, Inc. (2001) http://www.immagic.com/TOC/
elibrary/TOC/meteor/downloads/shibblth.pdf
Shibboleth v1.1 Software; Internet2 (2003) http://shibboleth.internet2.edu/release/shib-v1.1.html
Shibboleth Frequently Asked Questions—Internet2 Middleware; Internet2
(2003); http://shibboleth.internet2.edu/shib-faq.html
Shibboleth Overview and Requirements; Internet2 (2001) http://shibboleth.internet2.edu/
docs/draft-internet2-shibboleth-requirements-01.html
Shibboleth—Specification, Draft v1.0; Internet2 (2001) http://shibboleth.internet2.edu/
docs/draft-internet2-shibboleth-specification-00.html
—Nate Klingenstein
Technical Analyst
Internet2
Boulder, Colo.
SRW and SRU Acronym:
SRW and SRU
What it stands for:
SRW stands for "Search and Retrieve via the Web" and features both SOAP-
and URL-based access mechanisms. The URL-based version is called SRU, which
stands for "Search and Retrieve via URLs."
What is its purpose?
The main idea behind SRW (which encompasses both SRU and SRW) is the same
as in Z39.50. It aims to be a standard search-and-retrieve protocol, allowing
a single client to access many servers, and allowing a server to be accessed
by many clients in a machine-readable and automated way. One of the major benefits
it has over Z39.50 is that it lowers the implementation barrier by using XML
instead of the much more complex encoding used by Z39.50 (BER/ANS.1). Using
XML and CQL (Common Query Language) increases the human readability of the
exchanged messages, which contributes to this low barrier.
SRU is the simpler of the two mechanisms. A search request takes the form
of a URL with a base-URL and some parameters. The parameters are the query
itself and some additional parameters such as the start record and the maximum
number of records to be returned. The base-URL identifies the service that
will process the query.
Here's an example of a request URL:
http://www.host/cgi-bin/sru?query=shakespeare&maximumRecords=10&recordSchema=dc
The complete URL can be created dynamically by taking a user's search terms
and putting them together with a base-URL. In this way, the same request can
be sent to different targets by varying the base-URL.
The response is in XML, conforming to a simple schema (http://www.loc.gov/z3950/agency/zing/srw/srw-types.xsd),
and is therefore machine-readable. A very simple example looks like this:
<searchRetrieveResponsexmlns="http://www.loc.gov/zing/srw/v1.0/">
<numberOfRecords>1</numberOfRecords>
<resultSetId>20030311.179</resultSetId>
<records>
<record>
<recordPosition>1</recordPosition>
<recordSchema>dc</recordSchema>
<recordData>
<dc xmlns:dc="http://purl.org/dc/elements/1.1/">
<dc:title>Hamlet</dc:title>
<dc:creator>Shakespeare, William</dc:creator>
<dc:type>book</dc:type>
</dc>
</recordData>
</record>
</records>
</searchRetrieveResponse>
This approach makes it easy to have the same query broadcast to different
servers and to have the returned data processed or presented in the same way.
All Web-based search-and-retrieve applications do something similar; a distinctive
feature of this protocol is that it standardizes the requesting URL and the
response by returning pure XML data without complicated HTML layout. Thus,
SRU is a simplification of what we already do in HTML.
SRW does basically the same thing, with two main differences: 1) SRW uses
SOAP (Simple Object Access Protocol) as an extra protocol layer. 2) In SRW,
a request is sent as XML via an HTTP POST instead of a URL using an HTTP GET.
SRW can therefore take more complex requests as input.
Group behind it:
SRW is being developed and maintained by the Z39.50 Implementers Group (http://www.loc.gov/z3950/agency/zing).
Does it replace or update a previous standard?
No
What stage of development is it at?
The specifications of version 1.0 have been evaluated during a 9-month testing
period by approximately 10 implementers. Version 1.0 defined search and retrieve,
sorting, result sets, and explain. Currently, the specifications for version
1.1 are being defined; they will also define the scan operation. The number
of implementations is growing steadily, but it is not easy to foresee when
SRU and SRW will exceed Z39.50. Due to existing investments in Z39.50, the
use of SRU/SRW-Z39.50 gateways will facilitate acceptance of SRU and SRW.
It is expected that SRW will mainly be used for central services that access
SRW services on one side and give the user access via HTTP/
HTML with minimal browser requirements on the other. SRU, however, offers the
possibility for quite a different approach. As more and more browsers support
XSL transformations in the browser, SRU can be implemented quite easily by
anyone with some basic knowledge of XSL, without the need for an organization
offering a central server or service.
Pros & Cons:
Pros: In many cases, sometimes with additional JavaScript,
full portal functionality can be created as a simple XSL/HTML page running
in the browser and giving simultaneous access to different sources.
Cons: This additional JavaScript might cause people to refrain
from adopting this approach, since using JavaScript might increase the security
risk.
—Theo van Veen
Project Leader
National Library of the Netherlands,
Department of Research & Development
The Hague
Netherlands
Participant in the SRU/SRW Developers Group |