FEATURE
Project Lefty: More Bang for the Search Query
by Ken Varnum
PROJECT LEFTY is a search
system that, at a minimum, adds
a layer on top of traditional
federated search tools that
will make the wait for
results more worthwhile for researchers.
In the aggregate, libraries spend vast amounts of money on electronic databases. In the aggregate, they are not utilized as extensively or efficiently as we librarians would like them to be. Traditional federated search has been the gold standard of article discovery for years. The expectations for speed and apparent relevancy brought forth by “web scale discovery tools” (in Marshall Breeding’s phrase) such as Google Scholar and Serials Solutions Summon in recent years have made traditional federated search tools seem clunky and unwieldy. This latest generation of search tools highlights the unpleasant side-effects of brokering searches among multiple targets and integrating the results: The old method is slow, and while the results may well be worth waiting for, library users don’t want to. Still, the newer tools have their faults. They may search “everything” the library offers, but it is often unclear exactly which databases and journals are being searched, and the relevancy rankings are arbitrary and largely out of the library’s and the user’s control.
What is lacking is fine-tuning of searches based on who the patron is, what they are researching, and what level of academic investigation is appropriate. Article discovery tools must, on a query-by-query level, search the right databases (that is, databases specifically relevant to that particular search query) at the right level of academic inquiry (that is, the databases are appropriate to the academic level of the user in the subject domain they are searching), and use the right query (that is, domain- or database-specific vocabulary). Thus, I propose Project Lefty (three rights, of course, make a left).
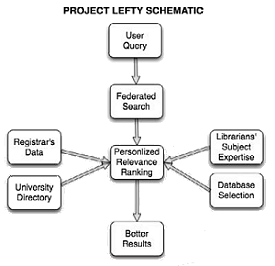
Project Lefty is a search system that, at a minimum, adds a layer on top of traditional federated search tools that will make the wait for results more worthwhile for researchers. At best, Project Lefty improves search queries and relevance rankings for web-scale discovery tools to make the results themselves more relevant to the researcher’s specific query. Project Lefty has three components, each directed at a particular right.
Determining the Right Database
Picking the correct database or databases for a particular user’s specific query is a challenge perhaps best met with the traditional reference interview. In Project Lefty, we accomplish this in an automated way, through a two-step process:
1. The first is to understand the contents of the databases themselves. Vendors already provide descriptions (both narrative and keyword) of their products. Librarians have added additional metadata. These collective descriptions can be improved by adding abstracts of the sources indexed by the database.
2. The second part is to map the user’s query to a well-defined set of databases. There are several possibilities for doing this. In one method, we could use historical searches and targets to predict the future. The University of Michigan (UM) Library already has a “database finder” that maps a user’s query against historical uses of library-provided databases for that query. The databases that patrons frequently use to find results for that query are likely candidates for future searches. (See, for example, the left-hand navigation column on the articles search results for “middle east”: www.lib.umich.edu/article/General%20Interest/middle%20east.) Alternately, we could perform the query against a general interest article database (such as FirstSearch or Google Scholar) and perform an analysis of the first results to be returned to determine subject clusters. These subject clusters would then be mapped to narrower databases in the library’s collection.
ABOUT THE CONTEST
The Federated Search Blog (http://federatedsearchblog.com) held its second annual contest to increase awareness of and interest in federated search. The blog asked participants to describe the most impressive federated search application they’ve ever seen or imagined. Blog and contest sponsor Deep Web Technologies awarded cash prizes to the top three winners: Ken Varnum, Hope Leman, and David Walker. Industry experts Abe Lederman, Todd Miller, Helen Mitchell, Richard Tong, and Walt Warnick judged the submissions. In addition to receiving a $1,000 cash prize, top winner Ken Varnum participated in a panel discussion at the Computers in Libraries Conference, and his winning essay is published here.
The judges selected Hope Leman to receive the second-place prize for her essay “Not So Wild a Dream: The Science 2.0 Federated Search Dream Machine.” Hope is a research information technologist for Samaritan Health Services in Oregon, where she is helping to develop a service to help scientists and public health researchers find professional conferences and places to submit their research papers. Hope’s essay shares her dream of creating a federated search engine to help scientists with two key aspects of research: finding the current state of research on a topic and finding calls for papers and presentations.
David Walker received third place in the contest. David, library web services manager at California State University, produced a video titled Using Metasearch to Create a Journal Table of Contents Alerting Service. The video describes the work his library is doing to connect researchers to journal articles. The challenge is that while many publishers have alerting services to notify subscribers of new content, procedures for accessing the services vary greatly between publishers. Additionally, these publisher-provided services typically provide links to content that a researcher may not have permission to access due to authentication and location issues. David explains how combining a number of existing technologies overcomes these hurdles.
The blog received a number of other innovative submissions. Charles Knight, search editor for The Next Web, won honorable mention for proposing that federated search be used to mash up geographic data that is then projected onto a globe-shaped screen. Other submissions included applying artificial intelligence to search, developing common standards for publishers to follow to simplify the search and aggregation process, and chucking federated search altogether in favor of “small town librarians.”
Learn more about the winning contest entries at http://federatedsearchblog.com/category/contest-winners-2009. |
Determining the Right Academic Level
Figuring out if the researcher is likely seeking introductory, overview, or advanced information in response to a given question is the next step. We have a two-part strategy to figure out what level of information is most likely appropriate:
First, we need to make a best guess at the presumed academic level of the specific query. We can do this by pulling together a variety of “environmental information” about the person asking the question (assuming the user has authenticated), including the following:
1. For students, through accessing the registrar’s information, determining the courses in which the student is enrolled. If the query fits a course, we can assume that course’s academic level. For example, a search for “government” when the student is enrolled in Political Science 101 would imply a basic query. A student enrolled in several higher-level political science courses would imply a higher level of inquiry.
2. For faculty, inquiries in their subject domain (their academic department) would be assumed to be at the highest possible level. For queries out of their subject domain, a lower level of academic inquiry could be inferred.
3. For people who are not authenticated, or about whom we can make no inference, we don’t infer an academic level.
Second, we need to determine the specificity/academic level of the databases in the subject domain and then give higher relevance to items coming from the appropriately selected databases. It is not that we exclude databases with the “wrong” presumed academic level, but we give sources with the “right” academic level a relevance bump. We determine the relevance increase or decrease through any of a range of methods. The specific method chosen depends on what bibliographic data we have about the articles being returned from the search tool:
1. Running sample user queries (from historical query logs) against the databases to find which databases are the most general for that query and which are the most specific
2. Observing a user’s interaction with the system to tune the default behavior
3. Assigning broad levels (introductory to intermediate; in-depth; etc.) to specific journals beforehand and matching the user’s presumed academic level to citations in the result list
4. Over time, observing user behavior to learn which level of database a particular individual generally goes to (someone who goes to “high level” or very specific databases routinely has those weighted more strongly; someone who routinely goes to the more general databases has those weighted more strongly)
5. Recency—given a query in a subject domain, similar queries over time (by that user and by all users) influence sorting of results for future searches
By substituting vocabulary that better fits the subject domain and database, we enhance the user’s query to be better targeted. This can be achieved through search query analysis—what similar queries provide objectively better results. Expanding keywords appropriately requires understanding the subject domain of the query. Several approaches for this process include the following:
1. Using full-text materials available through the HathiTrust and other sources, combined with Library of Congress (LC) call numbers and/or LC subject headings assigned to those items, to assemble large bodies of text from current publications by subject area and to develop maps of search terms to the subject domains in which they most frequently occur
2. Using Google Scholar results to find best-fit articles for a given query, and then use those returned results to generate a better-targeted query by identifying common keywords in Google Scholar’s first few results
Outcomes
In the system just described, a first-year student who has not declared a major who is taking a history class and a full professor in the history department would both enter the same search query, “Boer war.” The student and the professor would get a very different set of results based on their different presumed level of academic investigation. The student would see general texts nearer the top of his of her results list while the professor would see more scholarly academic papers closer to the top. Because the professor frequently searches this topic and ends up at articles from two particular scholarly journals, articles from those journals are right at the top of his or her results list. (A librarian assisting either patron could perform a search as that individual so as to see the same results list.)
So what does this achieve? Without having to do anything at all different—beyond authenticating—the user gets a results set that is more likely to contain highly relevant content and gets content that is more likely to be directly relevant to the particular query. A customized relevance ranking is not much differently arbitrary than the one-size-fits-all approach taken by existing technologies. And this proposed tool can be used on top of an existing, or not-yet-developed, “old-school” or “newfangled” cross-database search platform. Sitting on top of the available technology, it improves results quietly, leading the researcher to better articles than they would find in an unassisted search.
Two colleagues at the University of Michigan Library have been instrumental in developing this concept and working toward implementation. Albert Bertram (lead developer, library web systems) provided constructive feedback and helped define the technical parameters of this project. Judy Yu (federated search developer, library web systems) is developing a pilot of the tool described herein.
|