|
|
| Libraries large and small are starting to realize the opportunities that open source software can make possible. |
Libraries large and small
are starting to realize the opportunities that open source software can
make possible. Open source is a buzz-phrase that is currently receiving
a lot of attention in the software industry and, increasingly, in libraries.
But what does it mean, and why is it important for libraries? In this article,
Ill try to answer those questions by drawing on our experiences using
open source software at the WRLC to develop a variety of Web-based applications
and services.
Peeking Through the Door
Even though its usually
licensed for free, open source software is not the same as free software.
There are free programs that arent open source, and there are costs associated
with any software besides the initial licensing fee. Open source means
that you are free to use, read, modify, and redistribute the source code
and program as you wish. Librarians will recognize this distinction immediately.
We strive to enable the free flow of information, but recognize the many
costs associated with running a library.
Others have taken the library/open source analogy pretty far. See the Web sites Ive listed in the accompanying sidebar for discussions of the open source movement and how it relates to libraries. Ive also included pointers to some of the open source software mentioned in this article and to essays on the technical and social aspects of open source. They include convincing arguments that open source software can be more quickly and reliably developed and enhanced than software distributed in binary format only.
At the WRLC, however, its the practical benefits rather than the philosophy that has attracted us to open source software. The WRLC is a regional resource-sharing organization established by seven universities in the Washington, DC, metropolitan area to expand and enhance the information resources available to their students and faculty. As is true for libraries around the world, many of those resources are electronic and require software systems for access and management.
When we evaluate software
to meet those needs, we are interested in whether it does the job and whether
we can afford both the software license and the time and resources to set
it up and maintain it. We will get the most affordable working solution,
whether it is open source or not. Obviously, open source software has an
immediate affordability advantage in our environment. It is usually free,
but even if we pay for a package, the open source license allows us to
deploy that software on as many computers and for as many users as we want.
How We Opened New Integration Opportunities
Finding a solution that
meets our needs is a more difficult problem, sometimes at any price. The
requirements of a library are pretty specific, and in our case we need
to meet the needs of seven libraries. No longer will a single monolithic
system meet all the requirements; we need to integrate various pieces together,
and that calls for some degree of openness in each of the pieces. For example,
our library catalog system is not open source, but the underlying database
structure is open to us, allowing integration with other applications that
can query the catalog database directly.
Open source gives us the opportunity for an even greater degree of integration. Even without modifying the source code (which we rarely do), by examining the code we can more easily see how the pieces of a program fit together and how we can plug our own glueware into it to connect multiple systems.
This is what we did with Prospero, an open source system for online document delivery. We chose to use Prospero because we were already using Ariel, which Prospero is designed to complement. Ariel, from the Research Libraries Group (http://www.rlg.org), is a commercial document delivery system for interlibrary loan that uses the Internet to transmit electronic documents to borrowing libraries where they can be printed out for patrons. Prospero lets us streamline the process for consortium member libraries by converting Ariel documents to Adobe PDF and posting them to a secure Web site.
But Prospero comes with its own user file and authentication mechanisms. We already had a patron information system where we combined data from library catalogs and our consortial loan system. We just wanted to add patrons online documents from Prospero to our system. By examining the source code for Prospero, we discovered how to disable user file updates from the Prospero client and create our own user file from the patron information system. When patrons log in to our patron information system, it can automatically log them in to Prospero so they can view and retrieve their documents.
This integration was made
simple because we could see exactly how Prospero worked by looking at its
source code. But it also required custom programming for our patron information
system in order to create and maintain the Prospero user file and give
patrons access to Prospero. Developing this kind of glueware has allowed
the WRLC to migrate to an environment in which all our services are delivered
over the Web in pages that integrate data from a variety of sources. And
open source software has provided us with the tools to implement this migration.
This Way Looks Familiar
The WRLCs central public
access information service is known as ALADIN (Access to Library and Database
Information Network). It includes an online library catalog, article databases,
image and other multimedia collections, and other resources. Since the
mid-90s this service has been available on the Web. Originally, this meant
that ALADIN provided Web interfaces to our catalog system and to locally
mounted article and image databases. But over time the locally mounted
information resources have been replaced by remote database services, and
the catalog system has required various add-on services and programs.
The WRLC needed a way to
manage the integration and development of this growing web of resources
and services. Without consciously adopting the philosophy, we turned more
and more often to open source tools. This was natural since we were building
on top of the Web, and the Web is built on top of the Internet, and the
Internet is built on, of course, open source software. Much of the basic
software running the Internet is open source, from BIND (the basic system
that maps host names to IP addresses) to sendmail (the mail transfer agent
for most e-mail on the Internet). The first graphical Web browser, Mosaic,
was an open source program, as is the Apache Web server, which serves over
60 percent of the Web sites on the Internet. The open source door, it turned
out, was already open.
The First Few Steps
Since we used Apache Web
servers, it was natural to start there to look for tools that could extend
our Web services. We were attracted to Apache JServ for several reasons:
1) Its based on the same object-oriented programming language (Java) we
were using to customize our OCLC SiteSearch system, 2) its highly integrated
with the Apache Web server, and 3) it implemented a robust framework for
Web applications including user session management and server load balancing.
The first JServ application we wrote was a simple system for uploading item bar codes from a portable scanner and producing shelf inventory reports by comparing the bar codes with the data in our library catalog. This application proved that we could use JServ to integrate data from our catalog system and external sources, and quickly put it on the Web. We were sufficiently excited to continue using JServ to develop increasingly complex and critical applications, including the patron information system referred to above, named (for lack of a more original title) myALADIN.
Meanwhile, it was becoming clear that we needed to adapt our core ALADIN authentication and menuing system to the changing environment in which we found ourselves. SiteSearch serves us well as a platform for delivering locally mounted databases. But now our system had become more of a portal to a variety of local and remote resources. As we attempted to integrate more disparate information resources, we found that our custom code was increasingly difficult to maintain when we added resources or upgraded SiteSearch. Adding a database to the Web menusa frequent occurrencerequired manual, error-prone changes to four or five initialization files and an mSQL database. Adding or changing subject menus was even worse.
SiteSearch is a highly extensible
system, but there were still things that we couldnt get it to do. For
example, we wanted to avoid forcing patrons to log in multiple times when
they accessed multiple services. Once they logged in to ALADIN, they shouldnt
have to log in to the proxy servers used to access some databases. But
there was no way we could find to verify that the SiteSearch session ID
we had saved in a cookie was valid. Perhaps if SiteSearch was open source
we could have figured out a way to do this, but without that advantage,
this past spring we decided to pull our patron authentication and database
menu code out of SiteSearch and build our own system using JServ.
An Open Source Application Architecture
Despite our initial successes
with JServ-based glueware applications, we were still learning how to use
Java and JServ, and we werent sure our code was the most efficient or
maintainable. With ALADIN we needed to make sure access was quick, since
the site had to handle over 100 requests a minute during peak times. And
we needed to be sure that customization changes for our libraries, such
as adding databases or changing Web page layout, could be done quickly
and easily without source code modifications or restarting the system.
One problem we had was separating the application logic from the HTML code. Our early systems had more lines of code emitting HTML tags than doing anything else. Any changes to the HTML formatting required modifying a Java class, recompiling it, and reinitializing the JServ zone to get the new class loaded. Again, open source software came to the rescue, as we found several free systems that encapsulate HTML in templates. Because the software was free, we downloaded three alternatives and tried them out to see which one worked best in our environment. We chose FreeMarker because it is a simple Java-based system that integrated well with JServ.
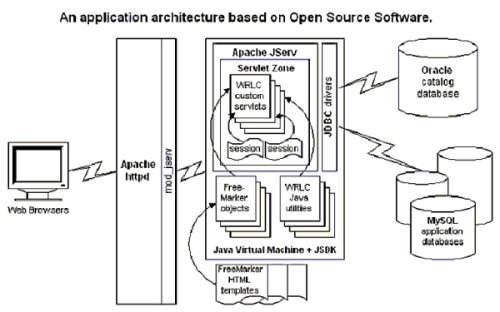
FreeMarker then became part
of our overall application architecture (see Figure 1), based on open source
software tools. This architecture allowed us to quickly rewrite our portal
system into a faster and more flexible system. Not only are the applications
flexible, but open source software allows us to modify and enhance the
architecture without making a big investment up front. A real advantage
of open source software is the ability to fully evaluate software without
making any financial commitment or dealing with sales people.
Supporting the Software
Of course, we have encountered
problems using our open source software toolset. But the problems arent
unlike those that come with any software. Probably the most serious problem
has been the steep learning curve. Documentation quality is variable (as
it is with commercial packages), and often you are left to figure out how
things work by experimenting. With open source software, if you are familiar
with the underlying technology you can always take a peek under the hood
to try to figure out whats going on. At WRLC, we arent going to get much
by looking at the code for the Linux kernel, but we were able to learn
a lot, for example, by looking at the Perl scripts that manage the Prospero
Web document delivery. The more popular the software, the more help you
can find to learn about it. So, you will find many books, Web sites, and
other resources about Linux.
The more popular software
packages also have more support options, including commercial support that
can be purchased. Even the smaller open source software packages, however,
have at least an e-mail list where you can get support from other users
and, often, the developers themselves. JServ, for example, has a very active
list to which the primary developer contributes frequently. Sometimes he
posts a dozen messages a day responding to questions or problem reports.
He doesnt suffer fools gladly, and gets particularly annoyed by questions
that are answered in the FAQ or other documentation available for JServ.
But I am happy to tolerate a little grumpiness in exchange for access to
the software developer.
Keeping the Doors Open
Those support options are
helpful, and may be sufficient for libraries using open source applications
like Prospero that work well and require little configuration. But doing
the things we do at the WRLC with open source software, such as developing
custom applications and integrating commercial, open source, and our own
systems, requires in-house support. Without a certain level of expertise,
it is impossible to even ask the kinds of questions that might result in
helpful responses on an e-mail list. We were able to make use of open source
software because we had a small programming staff that had experience using
UNIX and Web tools in general. Although open source tools allow the staff
to develop and integrate applications more quickly, their time and expertise
are not free, which is why there really is no free software.
However, if you have access
to some in-house IT expertise, then open source software can open many
doors of opportunity for your library. At the WRLC, we found that using
open source software was not unlike using any other software; its just
more flexible. That flexibility has given us the opportunity to adapt our
systems to meet the changing requirements of the wired information world,
and thats a door we need to keep open.
| Open Source Tools and Philosophy |
| Open Source Systems for Libraries
http://www.oss4lib.org This site is specifically geared to open source software for use in libraries. The Projects page lists open source projects for library software. The Readings page includes pointers to essays about open source and libraries, as well as books on more general open source topics. OpenSource.Org
Linux World
The Free Software Foundation
The Apache Software Foundation
FreeMarker
MySQL
Prospero
|
Don Gourley is director
of information technology and chief open source advocate at the Washington
Research Library Consortium in Upper Marlboro, Maryland. He holds an M.S.
in computer science from the University of ColoradoBoulder. His e-mail
address is gourley@wrlc.org.
| Table of Contents | Computers In Libraries Home Page |

{kind=link}