| Volume 16, Number 6 June 1999 |
| Report
from the Field
Search Engines: The 1999 Conference Visualization was the star of the show at the recent Infonortics-sponsored meeting in Boston by Susan Feldman |
Trends
Three themes emerged during these two intense days: visualization,
metadata and categorization, and pursuit of the elusive user.
Visualization was the star of this show. As James Wise noted in his half-day seminar on the subject, people are visual animals. We can process more visual information and process it more quickly if its in the form of graphs, charts, or pictures than if it is text. Those of us in information-intense fields are burdened with more text than we 1must be able to explore the information we receive in some sort of intuitive spatial format. Color, shape, and proximity to other shapes can convey information quickly. Landscapes and galaxies of stars are good approaches because they are familiar forms.
 |
| Figure 1 |
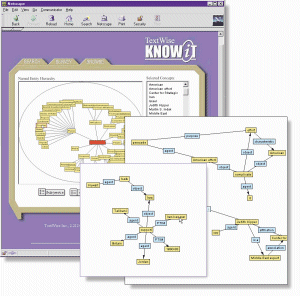
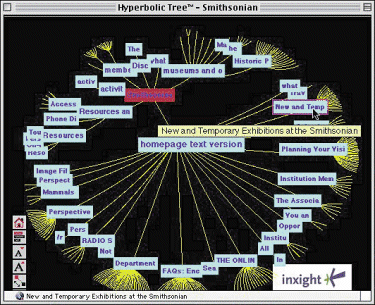
Many of the presenters at this conference were experimenting with visualizations to help the user navigate through large sets of documents, or improve a query. New data mining systems are also experimenting with visual displays. KNOW-IT from TextWise (http://www.textwise.com) shows two concepts linked by the kind of relationship that binds them. (See Figure 1.) Imagine that a system could show what caused an event to occur, in a visual format. The user would be able to grasp the significance of that relationship much more readily than if he had to plow through 10 documents himself. The InXight Hyperbolic Browser, developed at Xerox PARC, uses hierarchies to break up large collections of things into small usable chunks (http://www.inxight.com). (See Figure 2.) Both InXights and TextWises tools invite interaction. You are presented with top-level categories. Clicking on topics lets you drill down to more specific subjects, or, at the end of the road, to a list of documents in that category. How will people use this novel approach to browse for and explore information?
 |
| Figure 2 |
In contrast, LookSmart is using people to review sites for appropriateness, and also to assign them to a category. Its target audience is new arrivals on the Web. It is aimed at family usage, a G-rated search engine. LookSmart maintains that it needs humans to make these subtle judgments of quality and suitability. Note that this is one of several tactics Web search engines are choosing to distinguish themselves from the rest. On the downside, Peter Tomassi noted, you have to feed and entertain humans, but computers just keep going. For this reason, they are considering adding automatic categorization.
Dan Miller from Ask Jeeves described their human-centered process. Ask Jeeves tries to answer questions with the single best answer it can find. To do this, it is manually building a knowledge base of answer templates and question templates, rather than a collection of Web pages. Miller maintains that despite this being a manual process, it is quite scalable, since the process happens at the input stage, rather than at the time of searching. Ask Jeeves is getting faster as it adds more questions, since there are similarities between many questions. (If you want a review of a Ford Explorer, its easy to use the same source as an answer to other car reviews.) One promising application for this approach is in a corporate customer service department, which answers a finite number of questions within a defined domain. Dell Computers uses Ask Jeeves for this purpose.
In contrast, James Callan, of the University of Massachusetts, pointed out that it is difficult to create good categories because they overlap. Clear distinctions are hard to define. They require labor and insert lag time in the process. A list of 30,000 categories is difficult to navigate. Full-text searching is an attractive alternative. Most of the Web search engines are based on older search technologies. If they incorporated newer approaches, such as full natural language processing, better statistical models, or hub and link technologies like Clever, the search results might improve. It may be more useful to make documents easier to find, and to understand how people search than to return to categorization.
The value of this surprising return to an old library approach will
not be resolved soon. The trend we will see in information systems of the
future, I predict, is that they will combine as many entry points, views,
and sources of information as they can about a set of documents. The reason
is that different people need the same information presented to match their
particular need for information, as well as their own styles of searching
and learning. The University of Tennessees Carol Tenopir has done recent
studies that underline this need. She reports that experience, technical
aptitude, age, cognitive and learning styles, and personality type all
distinguish how people seek information. Of particular interest are Tenopirs
studies on the influence personality traits and emotional factors have
on how people search. What she found is that the affective domainemotions
such as stress, satisfaction, or frustrationinfluences searching behavior
as much as cognitive or sensorimotor factors. She has also studied the
differences in searching between novices and information intermediaries.
Both novices and professionals create search strategies based on their
personality traits, which is not a surprise. What we didnt expect is that
both of them also alter strategies based on emotional factors, not cold
hard logicrather an unpleasantly revealing fact for those of us who regard
ourselves as rational beings. Novices, however, are satisfied if they find
just one answer. Presumably, professionals seek additional confirmation
of accuracy, as well as other points of view. She expects that new research
in how people seek information, as well as new input/output devices such
as voice interaction, games, or wearable computers, may change how we interact
with computers. This research is critical if we are to design easy-to-use
information systems that can serve a spectrum of information needs and
users.
Other Highlights
Danny Sullivan, of Search Engine Watch fame, talked about portalmaniathe
shift to serving information instead of Web pages
and other Web search engine trends. Portals have sticky featuresfeatures
that attract users so that they wont leave the site. Anyone who has used
Web search engines recently must have noted the addition of directories,
chat areas, free e-mail, shopping, and content that resides on the search
engine siteto say nothing of ad banners. Search, says Sullivan, is becoming
much less prominent. However, Web search engines are also trying to improve
the relevance of results for popular queries. Since most users do not use
advanced search features, or enter complex queries, the Web search engines
are trying to direct them to the most popular sites for that query, or
they are creating directories (hence the interest in categorization) to
help the user find the right ballpark so that he can browse productively.
Sullivan predicted that we will see more use of nontraditional ranking
criteria (like popularity, or number of links to or from a site). He also
expects continued growth of directories, and more specialized collections
with less emphasis on comprehensive Web crawling.
Another highlight, for me, was an informal lunchtime get-together of Web search engine staff and several industry observers. Sullivan invited us all to discuss the possibility of establishing standards for search syntax, and also other topics of mutual concern. For more information on this, see http://searchenginewatch.internet.com/standards. At present, Sullivan has two proposals up for discussion: that all search engines be able to narrow a search by site, and that they all have the ability to locate an exact URL within their indexes. Participants also discussed the problems they are all having with the spamming that is so prevalent on the Web. The interest in this discussion is indicative of the need for working together on some common problems. As of April 29, the participants in the group are AltaVista; Excite; Fireball; Google; GoTo; HotBot; Infoseek; Inktomi; LookSmart; MSN Search; Netscape; Northern Light; Search UK; Snap; Yahoo!; Luis Gravano, Columbia University; Sue Feldman, Datasearch; Jakob Nielsen, User Advocate; Greg Notess, Search Engine Showdown; Avi Rappaport, SearchTools.com; Lou Rosenfeld, Argus Associates; Chris Sherman, Mining Co. Web Search Guide; Danny Sullivan, Search Engine Watch; and Roy Tennant, Web4Lib (http://sunsite.berkeley.edu/Web4Lib). A more extensive account of this discussion will be published in Searcher magazine by Avi Rappaport.
Steve Arnold, in a sweeping overview of the state of the online/information industry, noted a number of trends, some of which seem to work against each other. The consolidation of companies to create a vertical market works against the fragmentation of information sources. Computationally intensive technologies, such as visualization or multiple relevance-ranking techniques, are becoming mainstream as bandwidth and desktop computing power increase. There is a shift from fee to free software, which will make software business models scramble for income. Products and services are coming bundled together like a Russian matryushka doll, with search bundled with shopping or portals. XML and commercial XML (cXML) are more and more prevalent, improving display and search options.
Our online community often loses sight of the role government funding
has played in developing new technologies. Ellen Voorhees from NIST and
Terry Firmin from NCSC reviewed the TIPSTER, TREC, and SUMMAC programs.
Together, these programswhich fund development and compare and test information
technologieshave helped to create the excitement and ferment of the information
retrieval field. They fund development of new statistical and probabilistic
techniques, natural language processing, cross-language retrieval, filtering,
relevance feedback, retrieval from spoken text, and question-answering
systems. Their new Web track will examine whether Web documents are inherently
different from other types of documents. It will also test how well search
algorithms perform on large collections of text100 GB of Web documents.
NIST is also examining user behavior, queries, and multimedia information
sources through new competitive tracks. The SUMMAC program examines methods
for creating summaries automatically; this technology is in its infancy.
Not only are questions of what constitutes a good summary dependent on
the purpose to which it will be ut, but issues of copyright have yet to
be settled, since a summary or an extract may be considered a derivative
work. Nevertheless, experiments by various researchers have shown that
some systems have achieved a reasonable rate of accuracy. Wouldnt it be
nice to have the executive summary of your monthly report written for
you?
New Technologies
The plethora of new technologies we saw makes it impossible to highlight
them all. Here are a few that have left me dreaming of the very near future:
Predictions for the Future
David Evans of Claritech did a masterful job of wrapping up the conference
by giving direction and perspective to these many mind-boggling technologies.
He suggests that we are heading towards decision-support systems. These
information management systems would incorporate text-mining tools to integrate
information into the decision process. Data mining exploits patterns and
regularities, particularly in relational databases. Text mining will integrate
both relational and free-text sources. It will automatically analyze document
structure to discover fields, attributes, and values. It will use natural
language processing to parse text and determine lexical content. If we
can develop robust fact extraction, summarization, filtering, visualization,
agent, and learning technologies, then we will be able to use decision-support
systems to detect and track events such as the arrival of a new competitor,
or a new strain of disease-resistant bacteria. A new user interface that
frees the user from the underlying process is critical to the success of
this goal.
Many of the speakers offered their best guesses about the future. Here are some of the most tantalizing:
Next years Search Engines conference is scheduled for April 10-11,
2000, in Boston. For more information, check http://www.infonortics.com.
This years presentations will all be posted at that site.
Susan Feldman is president of Datasearch and a principal owner of Datasearch Labs, a new independent usability testing company. Her e-mail address is sef2@cornell.edu.