|
The R Technology Revolution: Relationship, Research Revenue and Michael Colson, Talavara LLC |
Web or intranet searching is shifting from presenting a list of hits to a richer, more complex presentation of information, delivering information in a meaningful context. Searching is a modern technological wonder, but algorithms can only do algorithmic functions. Humans perform other types of functions, including putting information into context and drawing relationships. Combining the best of routinized spider indexing functions, adding a soupçon of statistical analysis, getting people back into the search process that is the future.
Searching is becoming more concerned with relationships of many types. It is becoming a regular task. When a searcher needs help, there are different types of intermediaries on hand. The best research combines relationships among data, other researchers, and various technological gizmos. The Napster-Gnutella-Freenet revolution has just begun.
It appears that search functions are shifting toward a distributed network architecture (DNA). As a set of services that works to integrate resources, DNA is an open systems, client-server technology. DNA integrates information from any data acquisition system, simulator, information database, plant monitoring system, etc., and then facilitates the acquisition, archival, and retrieval of all types of information created or gathered. This model addresses the development, deployment, and maintenance of Web-based applications in an effort to build relationships among people and data.
The letter R may step out from the shadows of searching to the center stage. The themes that this article touches upon interconnect and directly relate to exploiting the relationship technology of the Internet:
Searching: One of the Core
Web Services
Finding information
is becoming a larger part of the average Internet users daily life. Searching
touches virtually all Internet users. Even locating information in ones
electronic mail folders can be a painful experience. In Outlook Express
it is difficult to sort mail from a particular sender by date. On most
intranet systems, such as those from Plumtree or mynet.com, among others,
pinpointing a particular news story requires patience as well. When one
wants a particular chunk of information that resides on a particular organizations
Web site, the searcher often finds the task time-consuming, tedious, and
sometimes impractical.
Yahoo! [http://www.yahoo.com] is one of the most-visited sites on the Internet. Like Lycos and FASTs services, Yahoo! has an international presence. The Yahoo! splash screen is not particularly user-friendly. Some might consider it cluttered [see Figure 1 on page 39].
Two points, however:
The Yahoo! visitor can locate information by pointing and clicking. No instruction other than the basics of pushing a mouse button is required.
Special services and features pop off the page. Good use of color and icons catch the users attention and invite a click.
Search-and-retrieval experts often ignore the Yahoo! search function. To a great extent, real live people create the basic listing of sites arrayed in a taxonomy or classification system in Yahoo!. Many on the Yahoo! editorial teams overseeing the 400,000 or so taxonomic entries have degrees in library or information science. However, Yahoo! really only directly indexes certain sites, now relying on Google to handle the rest.
When a user clicks on an entry in the taxonomy, a list of sites appears. These listings have been created by a Yahoo! professional or by a person who has submitted a site to Yahoo! Even the submitted listings that appear in the taxonomy have been reviewed and possibly edited by the Yahoo! editorial team.
At the bottom of the Yahoo! taxonomy pages links appear that invite the user to review a list of the 101 most useful Internet sites. A click triggers an advertisement for the magazine, Internet Life. For users who want to explore the news, Yahoo! offers a point-and-click approach plus an advanced search function. Based on information provided to our researchers, however, fewer than 10 percent of Yahoo! news users access the advanced searching function [see Figure 2 on page 39].
The quest for better search-and-retrieval systems continues. AITs Web site [http://www.arnoldit.com] provides links to more than 600 Internet directories and search engines that index content outside of North America. Within North America, the number of search engines and directories runs into the thousands. These are some of the more interesting new services:
The search service that really breaks new ground is Napster, the embattled file-sharing site [see Figure 3 on page 39]. The music industry has worked diligently to fundamentally alter the Napster service, but the technology of distributed content and virtual indexes is moving faster than the music industrys copyright lawyers. [A fierce legal battle swirls around Napster and its threat to copyright infringement. At one point, a federal district court ruling threatened to shut down the operation. By the time you read this article, this may have occurred, but at presstime, the 9th U.S. Circuit Court of Appeals had established a three-judge panel to hear arguments in early October. The recording industry wants the service shut down, but a diverse array of groups ranging from the Consumer Electronics Association to the Association of American Physicians and Surgeons has filed friend-of-the-court (amicus curiae) briefs on different aspects of the case.] Gnutella and Freenet offer similar functionality, with the virtual directory distributed across different machines, not centralized in one location.
The Napster interface provides a glimpse into the functionality embedded in the concept of distributed network architectures, where the opposite of a centralized repository and index exists to satisfy requests for information:
Gnutella, Freenet, and other distributed or virtual indices will have a significant impact on search and retrieval over the next 2-3 years in Internet time. The overhead associated with using a series of scripts like Inktomi, Northern Light, or Alta-Vistas Raging.com service to index the Web is enormous. When users do the indexing, core network functionality creates a virtual directory available for searching.
One new service, InfraSearch [see Figure 4 at right], uses the Napster distributed directory paradigm, combining both the technology and pricing mechanisms. The developers of InfraSearch came from the University of California-Berkeleys Experimental Computing Facility (XCF) and were responsible for Gnutella.
A publisher or information producer with content provides Napster-like information, substantially self-defined, to InfraSearch. A query returns a pointer to the file plus whatever meta-information that the submitter provided. InfraSearch can, with the information producers permission, spider the content and automatically create the brief description and the pointer. Content providers can specify if the information is provided without a fee or carries a per-view surcharge. The beta version of the service provides access to content from Moreover.com and Yahoo! Finance, services that carry both free and for-fee information.
When a document is located, a click takes the user to the publishers site where they can view the document for free or after paying a fee. Infrasearch uses the distributed network architecture in an interesting way that is the opposite of the old Dialog model.
As more and more PCs keep plugging into the Internet, the physical location of particular chunks of data that a user may wish to access has become increasingly irrelevant to Internet users. Many newcomers to personal computing have only foggy notions about directory structure, folders, file names, and the location of devices that actually hold the data or even the application software.
Inktomi and Google
have transformed the spidering business into a business model similar to
that of an Application Service Provider. Users rent or license an application
or, in Inktomis case, indexes of Web sites. When a person uses a Web search
feature on a Web site such as Microsofts or VerticalNets, they do not
use a search engine created or operated by that Web site. Instead, third
parties have created the taxonomy and index. It is cheaper for Webmasters
to rent a spidering utility and avoid the multi-million-dollar operational
costs of Web indexing.
Back to People
For information
professionals, however, the most interesting trend in search and retrieval
is probably the emergence of person-intermediated services. The trend extends
well beyond Yahoo!s directories, largely built by staff editors or people
submitting sites for inclusion in Yahoo! Table 1
on page 38 provides a roundup of some of the searching services that involve
humans in the search and retrieval process. Note that the approach varies
from volunteers (Mozilla open directory) to for-fee services (Guru.net),
with numerous twists.
Unlike About.com (formerly the Mining Company), expert services are shifting from search and retrieval that stores answers to anticipated questions to services driven by the asking of questions. The market leader in answering questions is Ask Jeeves [http://www.askjeeves.com].
The premise of About.com [see Figure 5 below] is that some individuals gather and maintain links to Web sites on particular topics. About.coms res ident expert on Web search and retrieval, for example, is Chris Sherman, an information broker.
How does Mr. Shermans listing of Web search sites differ from hits produced by a spider-generated service like FAST [http://www.alltheweb.com]? Presumably Mr. Sherman uses other sites indexes (probably ones built by spiders) to assist him in his research, so About.coms model is closer to Snaps or Yahoo!s editor-built directory. But in this case, Mr. Sherman is the person responsible for what appears in his list of links. It is quite difficult to find out what person or persons is directly responsible for a section of links at an Internet editorial shop like NBCi, owner of the Snap and Xoom directories, on the other hand.
How do the listings differ? First, Mr. Sherman constructed his core list using other research tools. The sites listed are those that he judges the most useful and pertinent to the subject of Web research. Second, if a person scanning Mr. Shermans links wishes to grouse or provide some other type of feedback, Mr. Sherman is available to answer questions by electronic mail or by telephone if the matter is urgent. Third, the links are updated on a cycle set by Mr. Sherman, not a script. About.com is a quite useful service, particularly for a person who wants to look at focused hits on a topic.
Ask Jeeves [see Figure 6 on page 40] is the natural language champ, at least in Internet space and stock trader visibility. For the month of June 2000, Media Metrix [http://www.mediametrix.com] noted that Ask Jeeves had climbed to the number 15 spot in unique Internet visitors. For that month, Ask Jeeves had about 12 million unique visitors or about 400,000 a day. This compares to America Onlines 2.6 million unique visitors per day. AOL was the most visited site in June 2000. Ask Jeeves is expected to lose about $40 million in the quarter ending June 30, 2000. The stock soared to 190 per share and sagged to 18 per share by the end of June 2000.
Experts in NLP scoff at Ask Jeeves. The user does enter a natural language query and does get an answer. Unlike the more esoteric NLP engines crafted at Carnegie-Mellon or Syracuse universities, Ask Jeeves looks at a question, like What is the weather in Capetown, South Africa?, and matches the question to a master list of 10,000 or so questions that Ask Jeeves knows how to answer by hitting a database of URLs and scripts. The user sees a template that allows them to select from a suite of likely answers.
|
So Whats Next?
To bring this
quick overview of Web search-and-retrieval to a close [see Table
2], one thread unites these quite different examples. Each of these
sites makes a concerted effort to put information into a context of some
type. Yahoo! uses a very easy-to-grasp taxonomy or simplified list of Library
of Congress subject term headings as the centerpiece of its site. This
core function is surrounded by mail, chat, discussion groups, and dozens
of other functions that allow the user to look for information in an interactive,
text-based environment. For the handful of users who want to formulate
a precise query, Yahoo! has crafted a form to walk the user through the
construction of a Boolean query. But most users do not use this feature.
The point-and-click approach allows the user to spot something of interest,
click on it, and explore other related topics in Yahoo!s presentation
of related links.
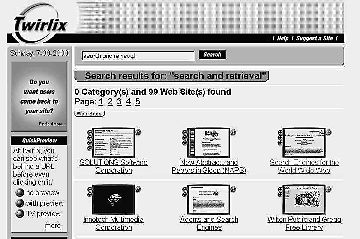
Consider Twirlix [see Figure 7 on page 40]. When a user does a query, Twirlix runs a query over its index of Web sites. Each hit display carries a thumbnail picture of the Web site plus a brief textual description of the site. The company calls this Quick Preview. Twirlixs TV-Preview option presents a list of sites with Quick Previews, QualityRatings, language, and site name but presented consecutively from left to right in order to get maximum information on a single page.
As noted, Napster, Gnutella, Freenet, Infrasearch, and the other virtual directory searching services make users and their information needs the focal point of the service. A searcher has a direct relationship with another user who has created the index pointer and created the file to which the index entry points. In effect, these new distributed services could disintermediate other Internet middlemen from the search-and-retrieval process. This is unlikely, however, because people want vetted lists of sites. Napster has, like Yahoo! and Lycos, created a host of what might be called regular communication tools. There are bulletin boards, chat groups, communities, and similar services to allow the users of distributed services to talk and meet one another on common ground.
About.com and a number of person-centric search and research sites make an expert the center of focus. Questions, searches, dialogs, and other interactions are encouraged by these sites. The researcher is in close relationship to the person responsible for the links in the site and can, with a click or two, engage that person in one-to-one conversation.
Ask Jeeves allows the user to ask the system a question. The answer, however, is placed in a context. The user can scan the presentation of different ways to get the answer to a particular question. Like Yahoo!, Ask Jeeves presents a context-rich array of choices. Recently Ask Jeeves has followed Yahoo! in offering personalization services and other types of communication vehicles.
The relationship technologies or techniques in this handful of high-traffic sites follow a common theme:
|
What About NLP?
NLP or Natural
Language Processing remains a popular research topic among Ph.D. candidates
in information science. The Holy Grail they seek would have someone speaking
a query into a mobile device and the search engine understanding the query,
collecting results, and delivering them to the user.
NLP is computationally intensive, fiendishly expensive, and far enough in the future that only the most ardent optimists bet that an NLP search engine will unseat Yahoo!. Ask Jeeves is not NLP-based on sophisticated linguistic and statistical algorithms. Ask Jeeves matches a query to a collection of canned answers. When a match is found, the search is run. The company is upgrading its technology, but its importance in the development of Internet searching lies in its ability or attempt to offer a service that allows a user to enter a query and get a response in a second or two. True NLP engines are best demonstrated in computer research laboratories.
A study by NPD New Media Services [http://www.npd.com] revealed what information professionals have known for many years and what information scientists have verified with hundreds of Journal of ASIS articles: An Internet search returns better results when the user relies on multiple-keyword searches and the use of more than one search engine.
However, based on the study of 33,000 Internet users picked at random during the first quarter of 2000, 81 percent of Web searchers reported success finding the information they were looking for. The sponsors of the study were 13 Internet search engines, including Alta-Vista, America Online, Ask Jeeves, Excite, Go, Google, GoTo.com, HotBot, Lycos, MSN Search, Netscape Search, Web Crawler, and Yahoo!.
Another interesting finding: Nearly 45 percent of Web users search using multiple keywords. About 29 percent rely on a single word. Only about 18 percent of those surveyed formulate queries in the form of questions. Nearly 80 percent use the same keywords in different search engines. Only 19 percent reformulate their query. [To view the survey results released on July 17, 2000, go to http://www.npd.com or http://www.iprospect.com.]
The companys research summary noted that a Web site must rank in the top 30 results to get significant traffic. Most people do not scroll past the top 30.
The practical approach to NLP is to factor humans into the search equation. After all, even the least bright human can figure out some of the nuances that bedevil the use of spoken language to derive meaning from context, intonation, and implication. Search engines are finding out that humans are cheaper, better, and faster than most NLP engines available in the marketplace.
The R revolution
can be seen in the use of people, information in context, and communication
tools. The technology enabling these functions is remarkable. The use to
which the technologies are put are easy to understand. The consumerization
of the Internet has changed the Internet from a narrow communications channel
to a multifaceted one.
Metasearch Engines
Metasearch services
allow users to enter a single query, which is then passd on to a number
of search engines. Some services, like Ixquick, allow the user to specify
the engines to which the query is sent. Other services, like Copernic and
Bulls Eye, provide preselected lists of search engines for particular
types of queries. One bundle of search engines works for news searches;
another set for Web searches, and so on. Bulls Eye offers more than 60
selections of search engines, giving the user fine-grained control of the
metasearch function.
The popularity of technology that takes one query and runs it across multiple Web indexes stems from one painful fact. The spiders and humans building Web indexes cannot keep pace with the amount of new information posted to the Web each day. Furthermore, a larger and larger percentage of Web pages are dynamic and exist only when a user takes an action. Agents and spiders can be programmed to create pages from dynamic content, but it is expensive to create script libraries. As a result, Web indexes focus on the popular pages. A metacrawler plays the odds that most Web indexes have less than 30 percent overlap. The result is that the user takes advantage of the lack of duplication. The results typically appear in a list of results ranked by relevance. Thus, instead of looking at separate lists of hits, the metacrawlers provide some relationship among the results.
Seymour Rubenstein,
the creator of the ground-breaking WordStar word processing software and
Quattro Pro spreadsheet, has developed a remarkable metasearch engine for
his new company, Prompt Software [see Figure 8
on page 42]. In addition to querying dozens of Web indices, the software
can be aimed at intranet servers and special types of documents in Word
or PowerPoint format. In addition, the software includes a feature that
allows the user to see an abstract or summary of the information on a Web
page simply by holding the cursor on a sites hyperlink. But the most remarkable
innovation is Mr. Rubensteins algorithm for extracting a word list with
proper names and compound words. A user can scan the alphabetical list,
click on the precise term, and be launched to the Web page where that term
or phrase appears.
Popularity Engines
Popularity algorithms
are used to determine what to index and relevance. Stanford-incubated Google
is the pioneer in link analysis. A search on Google returns results based
on sites that have links to them. The idea is that the more important a
site, the more other sites will point to it the better the seed, the
taller the tree.
An alternative approach is to count the clicks. Direct Hit, hatched at the Massachusetts Institute of Technology, indexes sites that people use. The idea is that popular, important sites are used most often.
Blending the two
ideas is Ixquick [see Figure 9 on page
42], based in New York City. This site combines link analysis and click-stream
analysis. Sites that rank highly with both score higher in importance
than those that do not. Ixquick is interesting because it focuses on the
relationships between links, clicks, and the users query across text,
MP3, and image files.
What High-Traffic Sites Have
Discovered about Searching
Demographics.
It has been discovered that if a site does not get traffic from people
in the right demographic, it is difficult to demonstrate its success.
No one knows how many sites exist on the Internet. The number is somewhere in the millions, with an estimated billion or so pages. Estimates for the volume of data flowing into the Internet are equally fuzzy. Received wisdom argues for the Internets doubling every 3-6 months. Pick a number. The point is that there are hundreds of millions of users, sites, pages, or any other metric one wants to use to measure the Internet.
A Dartmouth College report claimed that search engines are struggling to keep up with the new content and changes to existing Web pages. According to the Dartmouth researchers, We were able to determine that one in five Web pages is 12 days old or younger. Only one in four pages is more than 1 year old. Not surprisingly, the top sites include a search function, but the days of pure search creating a Top 20 site have been left behind. Searching is not enough. [For a copy of George Cybenko and Brian E. Brewingtons paper, How Dynamic Is the Web?, go to http://www9.org/w9cdrom/264/264.html.]
With an estimated 600 new pages added to the Web every minute, search engines have two difficult task to perform rapidly. The first is to index the new pages as soon as they appear. This means that the agents being used to monitor Web sites must operate continuously from multiple servers and multiple network access points. Identifying changed pages places additional demand on the spidering infrastructure. When a change is detected, the spiders must reindex the site. The combination of monitoring for new pages and determining changes to previously spidered and indexed pages requires substantial amounts of money and technical talent.
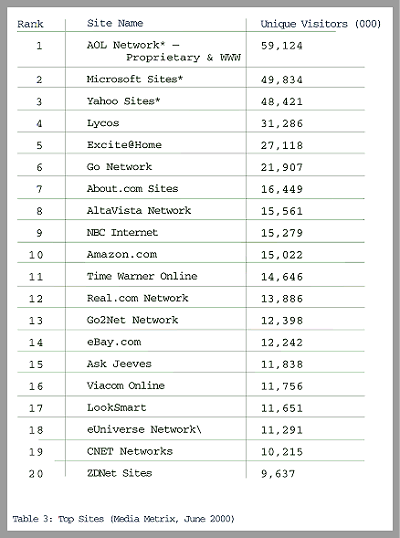
The surprising aspect of the Internet is that it is behaving in a decidedly old-fashioned way when it comes to user behavior. Technology wizards may stay up all night cursing America Online, but AOL is doing something right. It makes money. It has customers. It is one of the top sites on the Internet. A look at one of the popularity contests or hit parade of Internet success stories [see Table 3 on page 51] reveals the disparity between a typical company site with a few hundred to a few thousand hits per day to the top-performing Internet destinations (formerly called portals and now positioned as networks).
An inventory of the R technologies offered on these sites reveals the following:
First, look at the difference between the top five sites with an average number of unique visitors in the 43 million range. The average number of visitors to the sites ranked 16 through 20 is about 11 million one-fourth the traffic. The top five sites are not really sites. AOL, Microsoft, Yahoo!, Lycos, and Excite@Home are really full-scale online services offering searching, shopping, community, business information, and entertainment services.
Second, the shift from sites that provide one core service is profound. One year ago, sites that offered network services were limited to America Online and the much-maligned Microsoft Network (MSN). An Internet site provides a wide range of services. In fact, in order to capture clicks and unique visitors, these Internet sites are positioning themselves as networks. Seven of the 20 sites use network in their name as part of the sites positioning.
Third, the best way to grow is to purchase other high-traffic sites and roll those users into the mother ship site. Sites that have followed this practice are Lycos, Excite, NBCi, America Online, eBay, and recently CNet and ZD Net. CNet bought ZDnet in a staggering billion-dollar deal.
If we look in the business-to-business space, a similar story is unfolding. The explosion of business exchanges in the chemical, steel, and medical supplies industries is following the trajectory of the consumer Internet segment. A good example of the blend of back-office services and relationship technologies can be found in the sites built by Time0, a unit of Perot Systems, which has a partnership with companies such as Graingers OrderZone [see Figure 10 on page 42].
The features and functions of the business-to-business sites are similar to those found in the public network sites:
The Internet has functioned like adhesive tape since its inception 30 years ago. If we extend the sticky tape metaphor to a network infrastructure, the transformation of a redundant network into the global phenomenon becomes quite interesting. The original Internet performed the file transfer and machine access functions that its designers intended. But the Internet has proved to have powerful adhesive and adaptive qualities. Consider the concepts that appear in Basic R Technology Drivers.
Internet technology
gives ideas and technologies the breeding drive of lonely gerbils. Neither
gerbils nor the Internet is likely to cease breeding in the foreseeable
future.
Bottom Line What Makes Winners?
We started with
three Rs: research, relationships, and revenue, which boil down to three
metaphors or connotations. Our interpretation of the developments that
have been highlighted are somewhat new, and we invite comments and feedback.
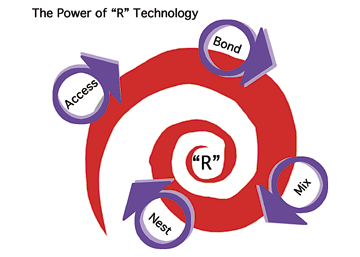
Figure 12 on page 46 illustrates the four stages or steps that users go through before they decide to make a particular site their favorite place. The first stage is access. Users have to be able to get to the site. Sites that respond slowly or put too many barriers in front of the user will probably not build a strong base of repeat users.
Once the user has access, the site must provide functions and services that allow the user to meet specific needs. The better the site is at meeting the needs that users may not be able to verbalize, the more likely users will return to the site and stay within it. Our research reveals that users under the age of 21 leave a site within 15 to 20 seconds of its splash page displaying.
The features that keep a site fresh place incredible financial and technical demands on the sites owner. Dynamic pages, personalization, and special features like Wireless Access Protocol (WAP) pages make static, text-based pages look stale, even when carrying valuable information. The site must provide ways for the users to interact. The site must also provide a broad, interesting selection of regularly refreshed services. AOL, Microsoft, and Yahoo!, among others, make it possible to refresh sites in near-real time. Such change keeps pages magnetic and enhances stickiness. Core communication functions make up the users part of the sites experience. The messages and information users post become homestead content. Users have a vested interest in the site.
The final stage for a successful site is enhancing the sites appeal as the only place to go for most services. America Online and Yahoo! are among the most successful nesting sites in the consumer space. Users literally do not know what to do if their AOL or Yahoo! page is not available for some reason.
Based on work sites large (US West Yellow Pages) and small (Talavara), a successful site follows at least four steps. Some can jump over all phases in a matter of weeks. An excellent example is the explosive growth and acceptance of the Napster music site. Other sites gather momentum over time, moving through evolutionary phases with almost predictable enhancements. Examples include the evolution of Amazon.com from a vendor of books to a Wal*Mart with homestead content, data mining suggesting books and music to the customer, and a widening stream of commercial products on offer. eBay has moved along a similar path with a foray into guarantees, credit-card billing, and a print magazine.
Figure 12 is like a whirlpool sucking uses toward an R. High traffic sites exert a suction of sorts. People send electronic mail to their friends about a useful site. Conference speakers call attention to sites that do something that can attract users and attention. Buzz, the vibration from viral marketing, gets people to take a look. If the site has something that offers value to the user, the user will keep coming back. People, even those not interested in New Wave music, will take a look at a hot site once to see what the excitement is about. The result is a digital cyclone that pulls users, a force field that turns the site into an electro-magnet pulling users into it.
The four stages or components of the diagram are certainly arbitrary. In order to have a successful site, people have to get access to it. America Online relies on carpet bombing prospects with almost unavoidable offers of free access. Other sites like the Food Networks pages about the Japanese cooking program Iron Chef happen without a budget and almost accidentally. Sites that offer day traders access to financial information from a high-profile source like Thomson Corporation charge for access. Sites that offer access for registration only generate revenue by selling names, setting up click-through and commission deals, or selling advertisements and sponsorships.
After they have people coming to their site, savvy site operators put text discussion groups in place. Others build systems that allow users to post comments on virtually any topic and hen use data mining tools or clustering algorithms to provide views of this grassroots content. Discussions and posting software are available from many different sources, including Pow Wow, Buzz Power, and ASAPware, to name just three.
As the message traffic grows, the successful site enhances the interaction options for its users. The high-traffic sites create environments that support live conferencing, automatic profiling and filtering of new messages, voice, video, and a constantly expanding blend of services designed to get people interacting with other people. Among the most interesting examples are sites that blend Internet directories and electronic mail access with experts who compile a topic-specific directory. If a directory listing fails to help, the user can talk directly to a person who knows about the subject.
The goal is to get users or customers who come to a site to stay there. Nesting is the high goal of the sites technology, marketing, and value. Our work with high-traffic sites supports what is emerging as common sense. Customers who stay within a site are more valuable than a visitor who clicks once and is gone in 20 seconds. Nesting users have value as eyeballs, potential purchasers of goods and services on offer, and as what is called, somewhat awkwardly, commitment. Site operators feel that a person who cares about a site will respond to surveys, provide information via online forms, and promote the site to others. The marketing information extracted from habitual users can provide important clues to the site operator about what features the core group of users and customers desire.
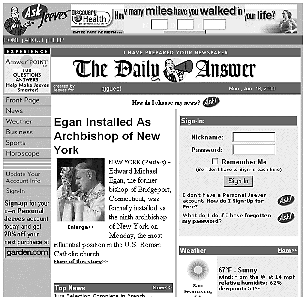
If we contrast the public Ask Jeeves page with the new personalized Ask Jeeves page [see Figure 13 above], three differences strike one immediately:
But does the same trend appear in the business to business market sector? Consider the screen from SageMakers intranet toolkit [see Figure 14 on page 48].
The similarities include a visually striking presentation, a combination of exposed information and news and one-click access to branded sources, and a tabbed interface that facilitates location of work-related information.
The future, however, is rich media. In closing, check out Finance-Vision, the multimedia Yahoo! service.
Although the interface is composed on many different panels, four key changes from standard Yahoo! are evident:
Why Relationship Technology
Matters
Jeremy Rifkin
singled out the R in his book Age of Access [The Age of Access:
The New Culture of Hypercapitalism, Where All of Life Is a Paid-For Experience.
New York: Jeremy P. Tarcher. Putnam. 2000. ISBN 1-58542-018-2]. Mr. Rifkin
calls attention to the importance of access for example, the disadvantage
to a person of exclusion from an online community. His book points out
that access is growing increasingly important.
The R in Mr.
Rifkins book stands for relationships in cyberspace and the everyday
aspects of life. The technologies that facilitate relationships have helped
high-traffic sites keep their users/customers coming back and staying in
the site for longer periods.
The technologies that drive relationships vary. Sites offer free Web pages so members can share their ideas with others. Geocities was one of the first of the free Web page services. Thousands of sites offer this service now. The technology is far from trivial, but once the trail is blazed, following becomes routine. Data-mining services like those pioneered by Firefly Technologies (acquired by Microsoft), Net Perceptions, and the less well-known bluestreak [http://www.bluestreak.com] allow a site operator to do the following:
bluestreak has developed a proprietary suite of statistical and analytic tools that determines what is used on a site. Armed with that data, bluestreak predicts click-stream patterns. What is remarkable about bluestreak is that its On-the-Fly technology does not use cookies. These chunks of data that Web sites write to a users computer have become increasingly controversial, particularly in Europe. Cookies allow a broad array of functions, including monitoring, without the user's knowledge.
Personalization is another major aspect of relationship technology. Yodlee [http://www.yodlee.com] is a developer of specialized personalization services that are being integrated into many sites. Yodlees technology can build a customized Web page for a user to provide a control panel for that users personal financial activities. Personalization services allow a user, customer, or member of a Web service to create a per-sonalized view of information. Yodlees customers include Intuit, AltaVista, and Sabre.
This rapid survey
of the four possible referents for R technology is not exhaustive. The
goal has been to illustrate how technology is creating an ever-more-personal,
one-to-one, and one-to-many ecosystem.
Wrap-Up: Where Will R Technology
Lead?
A review of the
four stages successful sites move through ties up the basic message of
this essay, namely, relationships appear to create a suction that pulls
users and keeps them stuck to the site. The network effect helped to
make telephones, facsimiles, and electronic mail important to have. Broad
use turned a curiosity into a necessity.
The behavior of the 180 million users worldwide suggests the Internet is simply a digital version of everyday human communications. Behind the glitzy Flash animations and the eye-straining typography of portals, the Internet delivers a booster jet for talking in text or voice, in images, and Web applications that provide digital versions of catalogs, calendars, and airline ticket sellers.
After electronic mail, search and retrieval is the most used service on the public Internet. The difficulty of locating the right bit of information at the moment it is needed still plagues users.
The richness of
innovation in search and retrieval is astounding. There are literally thousands
of Web and online indexing systems with mind-boggling variations.
Access
Access is the
starting point. Without access, there is no way for an individual to get
into the space where the relationships exist. A person without an electronic
mail address does not exist to some Internet users. A person unable to
enter a particular site will have little or no knowledge about the interac-tions
within that site. What information is available will be hearsay.
America Online
has defended its proprietary Instant Messenger service fiercely. Access
is limited to paying customers. Without value-added features like Instant
Messenger, the appeal of for-fee services like America Online would erode.
Similarly for-fee professional services place various restrictions upon
access. High fees effectively prevent certain individuals and organizations
from using LEXIS-NEXIS or Westlaw online information services. People without
the funds to pay a hefty monthly fee are not allowed to use some of the
financial information services available in the Thomsoninvest.com service.
Bonding
Savvy R technologists
want to give those with access ways to form relationships with people who
have similar interests and needs. Many Internet users take advantage of
real-time chat rooms offered by the major portals. Millions of peo-ple
post messages on various Usenet news groups, message boards, and special
interest services. For just one example, look at the Beverage Network [http://www.bevnet.com],
which features news, a bulletin board, and other information services for
its users.
The rapid evolution of Web search services into full-service information portals creates rich assortments of information, communication, and interaction for users. Lycos rapid rise from an also-ran to one of the top 10 most popular Internet sites has been fueled by its strong commitment to services that allow its users to buy, sell, talk, trade, and auction in a global setting.
Other sites have
discovered the power of real-time and asynchronous features as strong traffic
builders. Talk City [http://www.talkcity.com],
which began as a public forum for Internet users, has made substantial
headway in marketing its conferencing and discussion services to corporations.
It also functions as a public Internet site and an Application Service
Provider for groups requiring limited-access discussion services. A similar
surge in usage has accompanied the Webforia [http://www.webforia.com]
initiative to provide vertical discussion services, e.g., a service to
the information industry offered in conjunction with several well-known
trade publications. Webforia may require users to register for some features.
The company also offers low-cost Web software utilities for managing links
and generating reports.
Mixing
With a wide range
of clubs and messaging services, have sites reached the limits of simple
communication? Several problems plague community, club, and chat functions.
Many services are asynchronous. Users read and post messages at one time,
returning at another time to look for new postings.
In order to make messaging more immediate, Yahoo!, Gooey, and other services provide visual cues when the author of a message or the person selling a product is online. Real-time interaction provides more solid evidence that the Internet is not a casual activity, personally or professionally. Real-time information becomes critical to people who use the Internet throughout the day without ever ending their connection.
eNow was one of the first companies to combine real-time messaging and real-time indexing of the information posted in eNow discussions. The well-known services of Dèja News [http://www.deja.com] and Remarq [http://www.remarq.com] provide indexing of posts that often appear several hours to several days earlier. (Deja News offers a product-oriented selection of newsgroup content and a broad index of general discussions; Remarq provides a keyword search of newsgroup postings. Both services use some filtering.) eNow provides near-real-time access to information so that a person monitoring an eNow session for competitive intelligence or time-sensitive information may have a jump on those using less timely indexing services.
Net Currents [http://www.netcurrents.com] provides a competitive intelligence service that includes features permitting information extraction from newsgroups, bulletin board postings, and other types of information not usually indexed by such spiders as Gulliver (Northern Light), Inktomi, or Lycos. Its remarkable combination of spiders and automatic report generation features monitors dynamic environments, gathering information about a companys financial position, postings and messages in various online groups, and news sources. On a schedule set by Net Currents client, the company prepares a report about the company monitored. [A typical page from a May 2000 report appears in Figure 15 on page 48.]
In the R technology environment, the concept of mix is powerful. It connotes tools that allow individuals to mingle, exchange messages, comment, and create rich types of homestead information. (Homestead or grassroots information is created by individuals.
Unlike branded,
third-party information from such sources as Reuters, the Associated
Press, and The Wall Street Journal, among others, homestead information
may or may not be accurate. It does, however, have value.) It also provides
an ecosystem in which such advanced relationship technologies as data mining,
spidering, and automatic report generation can thrive.
Nesting
Where do Internet
customers spend their time? The goal of many Web sites is to build a loyal
core of customers who habitually return to the site. The sites most adept
at combining services and content for nesting are the most frequently visited.
The future of the
Internet may be glimpsed in Yahoo!s new service, FinanceVision. Before
America Online announced its television service, Yahoo! had trumped
the for-fee financial information services. A day trader can access a personalized
Web page, near real time news and stock quotes, Web pages, a search box,
and streaming video programs about companies and financial developments.
The service is remarkable.
Emotional and Social Bandwidth
The Internet puts
normal communications on steroids. It brings speed to what seems to be
a basic human need communication.
Electronic mail is somewhat time-shifted. It lacks emotional and social bandwidth. The innovators who thrive in the Internets ecology are interested in software, systems, applications, and features that increase the warmth, individualization, and richness of Web interactions.
America Onlines Instant Messenger brought ease-of-use and immediacy to text communication between buddies. A number of companies created me-too versions of Instant Messenger. The success of America Onlines application spread across customer service with robust commercial applications offered by Net Effects, Live Person, and eCRM (Electronic Customer Relationship Management) providers.
R technology boils down to using computer-assisted systems to bring human contact into what may seem to many a sterile experience. It represents a pragmatic response to adjusting a world that many people find far less comforting than the Norman Rockwell images of everyday life just 30 or 40 years ago.
As more nontechnical users embrace the Internet as a way to connect, the tools that make the users life easier, more pleasant, or more meaningful will better integrate into that users behavior.
Using technology to build, strengthen, or form relationships is a conceptual umbrella. The mechanisms of voice over the Internet or personalized greetings and recommendations are less important than the effect of these technologies on their users.
R is the suite
of technologies to watch. In the next six to nine months virtually every
major public site and most of the large intranet sites will place more
and more emphasis on technologies that personalize, anticipate, provide
enriched communications services, and, most importantly, build me.coms
for people with affinity.
Stephen E. Arnold
of Arnold Information Technologies (AIT) [http://www.arnoldit.com]
and Michael Colson of Talavara LLC [http://www.talavara.com]
both provide consulting services in R technologies and Web commerce.
Readers are encouraged to contact the authors at ait@arnoldit.com
and mcolson@talavara.com.
| Contents | Searcher Home |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}