| The Millennium Issue | Volume 8, Number 1 January 2000 |
The Answer Machine
Susan Feldman
Datasearch
| FIGURES |
 |
| Figure
1:
The Search Process |
 |
| Figure
2:
Steps in information-seeking |
 |
| Figure
3:
Concept mapping |
 |
| Figure
4:
Change monitoring visualized: Daily Diffs from InGenius Technologies [www.ingetech.com] |
 |
| Figure
5:
The Phrasier interface invites interaction, if you have a big enough screen |
 |
| Figure
6:
Cartias imaginary landscape |
 |
| Figure
7:
DR-LINKs interactive power search screen |
 |
| Figure
8:
Spotfire |
 |
| Figure
9:
Fedstats Relation Browser |
This information revolution is fueled by increased demand, by improvements in computer technology, and by our growing comprehension of how people seek and use information. As non-information professionals have become the dominant information consumers, they have begun to demand systems that can locate and manipulate information without arcane command languages and other traditional priestly rites. Unlike information intermediaries, whose main function is to search, knowledge workers use searching as a means to an end. This increasingly sophisticated group of information end users needs to find the right information quickly, analyze it, combine it into reports, summarize it for upper management, or use it to make decisions. They need a suite of integrated, intelligent information tools to make sense of todays ceaseless information bombardment.
Faster, bigger, cheaper desktop computers have the capacity to run newly developed information handling tools. News information systems will be built upon a foundation of linguistic analysis of language and meaning. To this, we add our growing understanding of cognitive processes. Research into how people think, combined with observations of how they interact with computer systems, is spawning the new discipline of human-computer interaction. New systems will draw heavily upon this field, as well as on cognitive psychology, graphic design, linguistics, computer science, and library science, each system with its own unique perspective on how to organize, find, and use information effectively.
The growth of corporate intranets adds to the demand. Companies are willing to invest in high-end, carefully crafted systems. Business cycles are growing shorter, while pressured employees spend too much time trying to handle too much information. Knowledge walks out the door as employees leave for new jobs in other companies. Intranets attempt to preserve this information and make it available to the entire company and will become an interactive venue for working with colleagues and with information in one smooth process.
Todays document retrieval systems lump all information needs into a single process. New information tools will separate these different needs into categories and provide specific tools for each kind of need.
Here are some of these search types:
The Search Process
How do we search
for and use information? Do end users differ from information intermediaries,
and if so, why? Can we differentiate types of searches and develop specialized
tools to improve our finding and use of information? These questions and
more must be answered as we set about designing the next generation of
information systems.
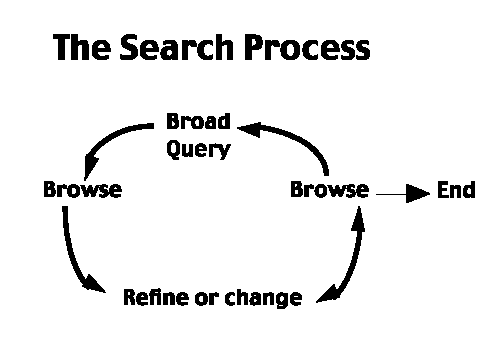
Searching isnt linear. We know that people engage in an iterative, or circular process when they seek information (see Figure 1 on page 61).
After testing the search behaviors of both end users and information professionals for the last 5 years, I believe in the inherent differences between how both groups search. This is not surprising, but it has little to do with the skill or training of either the information professional or the end user. Rather, these groups differ in their fundamental motivation for searching. End users know why they are searching, even if they dont articulate their information needs well. Success is defined by an answer to their information needs. They will know it when they see it. Therefore, they will more likely enter a very broad query and then browse. In fact, given a choice, they will enter the search cycle by browsing first and then refining their browsing with a query. This explains the popularity of directory sites like Yahoo!.
In contrast, the intermediary has only the end users question to match. Success is defined by the best possible match. Therefore, intermediaries focus on precision. Their queries tend to be much narrower and they will search before they browse. A broad query to the information professional is unprofessional, sloppy. When we criticize end users for their lack of searching artistry, we are often mistaken. They need to browse and browse broadly (see Figure 2 on page 67).
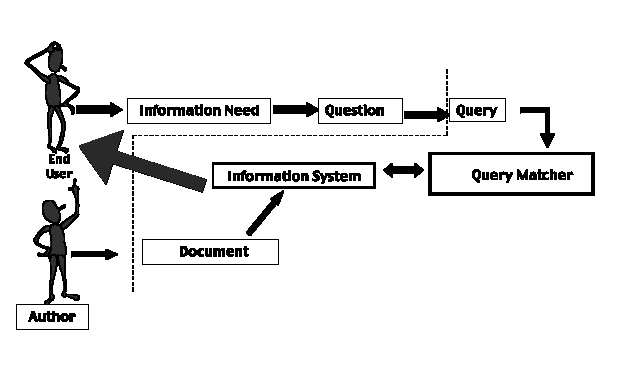
Most of todays document retrieval systems match queries to documents. These systems address the middle of the information-seeking process, enclosed in the dotted lines. While we may complain about the results, in fact, the systems do a pretty good job of matching the actual query received. However, the systems ignore the two outer ends of the process, offering no help at all in translating information needs into questions and then into acceptable queries. The systems do little to help the user understand and analyze what the system returns. So, while the user actually receives some good matches to his query, the query rarely reflects the information need behind it.
Yet, if the information need is not represented accurately, then the results returned will at best intersect that need spottily. Todays information systems require the searcher to extract terms that have the best chance of representing the question, while at the same time, eliminating extraneous or unrelated documents. We usually resolve this dilemma by using lists of nouns or phrases that represent the concepts in the question. In the process of formulating a query, we eliminate the actual meaning of the question because we strip away the context.
Look at the list of questions in the Stinkers sidebar on the right. A real Answer Machine could answer these questions, and more. It should:
If you approach your information system as a whole, then you will implement each new technology as a brick within an entire edifice. You could implement each technology separately, but ultimately, integration of these technologies will create a knowledge management system and even a decision support system. Without this vision, you may end up with so many oddly sized bricks that you will have to start again from scratch.
The system you
build should adapt to user needs and integrate information in any format.
It must reveal patterns and trends in information, because patterns and
trends are usually more significant than discrete facts or nuggets. And
above all, it must deliver answers to questions.
|
1. Identify bacteria in the process of becoming drug resistant. 2. Identify Bermuda advertising campaigns that promote the island as a tourist attraction. 3. Provide articles and case studies on attitudes of companies towards media relations, including best practices for approaching the media and trends in media relations. 4. Provide information on issues preparedness (i.e., rationales for why companies should be prepared to manage a crisis or issue in advance and how companies can effectively manage a crisis or issue). 5. Provide information on thought retreats/seminars/executive meetings, CEO retreats, and customer entertainment/appreciation events. 6. Identify books or articles that discuss how artworks through the ages have represented oral hygiene and dentistry (for example, is there a reason why the Mona Lisa doesnt smile?!). 7. Identify emerging competitors in X industry. 8. Where should I go for my vacation in January if I dont want to spend more than $600 per person and I dont like crowds? Id like to go some place warm with nice scenery, somewhere near an ocean. 9. How many widgets will Zambia manufacture in the next 5 years? I just want a number for each year, not a pile of documents. I need this in a half-hour, by the way. 10. I need to keep up on new information technologies as they appear. (This means that I need to identify new terms and also to drop those that have become outdated.) 11. Tell
me when my competitors have come out with a new product. I dont want any
other press releases.
|
The Foundation
Any retrieval
system must distinguish between one document and another. The system relies
on indicators that determine what a document is about. It also tries to
differentiate between documents mostly about a topic and those merely
somewhat about a topic. Unique terms or phrases often serve as good discriminators.
However, unique terms are hard to find in some areas, such as business,
which use very common words to mean something quite precise. The sample
queries Stinkers offer good examples of this problem.
To best determine a documents meaning, ask a subject expert. Indexers do this for a living. However, while experts may agree on broad subject areas, they may differ on which terms to assign to a specific document. Some studies done on indexer consistency found that indexers assign the same term to the same document only 50 percent of the time. Indexers do classify documents in the correct general subject area, even if they dont assign precisely the same term. They dont put financial institutions under environmental science.
Why, then, dont we stick to human classifiers to determine what a document is about? There are several reasons. First, that 50 percent consistency rate is quite troubling if searchers use thesauri to aid in query formulation. Assigning the wrong term can eliminate a highly relevant document from a retrieved set. Second, human indexing is slow; it adds weeks, even months, to the time it takes to make something available online. With real-time publishing becoming an accepted practice, we need other reliable means of distinguishing the relevant from the irrelevant. Third, the sheer volume of information is too great to try to classify it all manually.
Given that we must
find an automatic means to select the best documents for a query, how can
we teach a computer to recognize a good match?
Statistics and Probability
For all that searchers
talk about words, terms, commands, and other linguistic phenomena, computers
really understand only numbers. Every ASCII character, every letter in
the alphabet, must be translated into a sequence of ones and zeroes before
a computer can crunch it. Boolean commands work quickly because they are
mathematically based. One of the ironies of online searching is that its
practitioners consider themselves to be word rather than math people.
Yet, they handle Boolean logic with aplomb.
The genius of people like Gerard Salton lay in their recognition that text contains predictable patterns. These patterns can be described mathematically, so that computers can detect them and then perform statistical and mathematical operations on them. For instance, it seems obvious that the more a document is about a subject, the more times words dealing with that subject will appear in the text. Conversely, these terms should not appear very frequently in documents not about that subject. This is the rudimentary idea behind relevance ranking in retrieval systems.
Clusters of certain terms are even better indicators that a document is about a particular subject. The appearance of co-occurring terms will determine more precisely when a topic is central to a document. None of this requires that we understand the meaning of the words, merely the patterns the words display in the text.
Needless to say, we could embellish this principle by saying that words in the title are more important than words in the body of the document. We could add that the closer together subject-relevant words appear, the more likely the document is about what we are searching for. Or, if the words appear in a lead paragraph, they are more important indicators of the subject than if they appear in paragraph five. This is what skilled searchers do in crafting a search. It is not magic.
If we can describe these patterns, we can program a computer to find them. The first mathematical operation that search engines do is to count, something that computers do very well and very fast. Computers count the number of times a term or terms appear in a document, then assign a weight, or number, that represents this count to distinguish one document from another. This weight calculation usually takes into account how rare the term is in the whole database how many times it appears in every document in the collection. Rare terms are often good discriminators and receive a higher weight.
Search engines may also truncate terms to include plural and singular forms. Extra weight often attaches to terms appearing in the title or lead paragraph, as to documents which contain several query terms in the same sentence or in the same paragraph. Most search engines also normalize results to take into account variations in the length of documents, since longer documents will probably contain more occurrences of a term. When a search system matches your query terms to documents, it adds up the weights for each query term that appears in a document and assigns a score for that document. Then it compares all the scores and presents the highest first. This is relevance ranking in a nutshell.
Statistics and patterns enter into advanced retrieval systems in a number of other contexts. For instance, in order to determine whether a document matches a query, the system must calculate the similarity of the document to the query. The human mind does this without trotting out an algorithm. Computers must translate both query and document into some sort of representation. About this task, experts have written whole books.
One approach is to translate both query and document into a vector a line which goes off at a specific angle from the center of an imaginary space. Think of this space as having a signpost at the center, with each individual sign pointing in a slightly different direction. The words in the document all point to specific directions in this imaginary landscape. Documents containing similar words will point in the same general direction; the more similar those document terms, the closer their angles will be to each other. We can measure these angles to give us a degree of similarity. This vector space model can help calculate relevance ranking, but it can also determine clusters or clumps of similar documents. This is the basis for most of the star maps or imaginary landscape visualizations used to display the contents of a database or a retrieved set of documents.
These statistical techniques work surprisingly well in the majority of cases. But these techniques do not work well for every query. That is the nature of statistical methods. When we hit an exception to the rule, the errors can be glaring, unlike human errors. For instance, when a query contains both a very important concept expressed in an extremely common term and a very minor concept expressed in a rare term, then the rare term may skew the relevance ranking, since it has a higher weight than the common term.
Remember also that
statistical systems do not understand a query, but operate on the numbers.
Many meanings for the same word elude this kind of technology. Financial
institutions may be classified as environmental science, if the word is
bank. However, since bank will not appear in combination with other environmental
terms, if a query is more than one word long, a statistical system would
rank such a false drop low. Hence, search engines look very stupid by making
errors that any human with half a brain would never make. This could explain
why search engines have such a bad reputation among most professional searchers;
their errors are unreasonable. That is because the meaning of the terms
being retrieved is not part of the equation for statistical processing.
Natural-Language Processing
In order to build
a state-of-the-art information system, one must extract as much meaning
as possible from each document. A list of words, or even words and phrases,
is not enough. Context and meaning must be preserved. Only a system able
to distinguish meaning can return articles about terrorists instead of
rugby matches when asked for attacks, skirmishes, and battles in Rwanda.
A meaning-based system will also know to return predictions about future,
not past, production of widgets in Zambia in Question 9 of our Stinkers
list.
To create an advanced information system, first one must build a knowledge base. This base will contain all the documents in the system and their words, but also added information to resolve meaning and dissolve ambiguities. A good natural-language-based system provides the foundation for this system, because it parses sentences thoroughly, extracts meaning from context, and is smart enough to realize that if the year is 1999, Hilary Rodham Clinton and the first lady are the same person. A document-processing tool is required that can extract and store many layers of meaning, as well as automatically categorizing documents and identifying all variants of proper names. Each unit of meaning may also carry a time stamp relating to the content, not to the date on which someone added the document to the database. With relevant dates in place, later tools can extract automatically chronologies of events. Chronological information also enables the system to distinguish between first ladies Barbara Bush and Hilary Clinton, depending on the time and context of the question. The information in the knowledge base should also be retrievable as separate units, such as a single sentence or paragraph, if we want it to supply direct answers to questions.
I stress this knowledge base building step because most organizations will not willingly invest the money, time, and effort needed to design a knowledge base more than once within a few years. Any future advanced information tool will operate on the contents of this knowledge base. Therefore, extracting as much knowledge as possible should increase the flexibility in the future to adopt new technologies as they arrive. We cant know now what tools, in what formats, research and the market will deliver in the next 5-10 years. Compatibility will always be an issue. However, raw knowledge does not change. The more handles that you create to grab a piece of information, the more chance that you can retrieve it when needed. This is the same principle that advises digitizing at a high resolution when scanning collections: Build the foundation wisely and richly, because youll never be able to start again from scratch.
As we build advanced information systems, we will require that the systems understand text as we do. Natural-language (NLP)-processed-based systems are the only ones to answer this description at present. While NLP systems match terms, as both Boolean and statistical search engines do, the systems also extract meaning from syntax, built-in lexicons, context, and even the structure of the text itself. This is what humans do to figure out what a document means.
Many people feel
that statistical and NLP systems wont work as well on bibliographic databases
because their forte is full-text searching. True, these systems are not
designed to work well on document records that do not contain substantial
text. Therefore, it is said that bibliographic records such as those appearing
in a typical library catalog are not good candidates for these advanced
retrieval systems. However, I have found these systems as effective as
Boolean systems in searching through bibliographic databases, because most
can default to a relaxed Boolean query if necessary. As an added benefit,
the ability of the systems to relax the strictures of a query means that
occasional typographic errors will be ignored in relevant records that
a Boolean system would eliminate from the results.
Intelligent Agents
Imagine an information
system that learned what you sought and began to anticipate what you would
like to see. While this may sound like Star Wars, in fact, this capability
exists in embryonic form today. Interactions with todays systems are fixed
in time. The searcher must change a query in order to find documents not
already retrieved and to add new indexing terms manually. We need systems
that adapt to both the changing interests of the user and to changes in
the terms used to describe each topic. Machine learning techniques can
make an information system dynamic.
For instance, suppose 3 years ago you set up an alert for anything on information retrieval. If you didnt change your Alert profile, you would miss all the articles on data mining, knowledge management, or automatic summarization. An intelligent agent system could detect the rise of these new terms. The system would find clues in the appearance of data mining as a co-occurring term with information retrieval. Or, the agent system might note that you were reading articles on data mining and ask if you wanted to add that term to your profile. It might be programmed to follow new Internet links from sites that interested you; or, it could run an updated query periodically on all the Web search engines and then follow those links. This is of immense importance in a world in which, in 1997, a Reuters survey found that most professionals spent more time seeking information than using it.
Intelligent agents are software programs that use machine learning. Agents do not have innate intelligence. Although agents can operate in situations that have underlying patterns or rules of some sort, agents cannot work in complete chaos or with random input. The patterns or rules that they rely on may be described by humans or developed by the agent-based system itself. An agent system develops rules from sets of representative data and queries a training set. During the training period, system agents learn the best matches by trying out various matches and receiving corrections from human input. Eventually, agents build a pattern for what constitutes a good match.
Agent systems are autonomous in other words, they can initiate actions within a carefully defined set of rules. They are also adaptable, able to communicate with other agents and with the user. Agents may be mobile, traveling along the Internet or other networks in order to carry out various tasks, such as finding or delivering information, ordering books, or monitoring events. Most importantly, agents can alter their behavior to fit a new situation. They learn and change.
Some agent systems exist today. See the Botspot [http://www.botspot.com] for an extensive list and description of such systems. The agents in the Microsoft Office suite are only a beginning. They are not adaptable and they follow set rules. These agents offer hints, take and sometimes answer questions about functions of the software, and are mildly amusing. Eventually, we can expect agent systems to adapt to our preferences for formats or other repetitive actions we take like opening applications in certain orders or checking e-mail at a certain time of day and will perform these tasks automatically.
Eventually, agents will play a big part in the decision support systems now in development. These systems will use a knowledge base to find and compare previous situations that might apply to current problems, offering alternative solutions and perhaps creating scenarios for each alternative.
These three disciplines
statistics, natural language understanding, and intelligent agents
form the foundation for understanding and using the information tools of
the future. While it will be possible to use these tools and never understand
their inner workings, those who delve below the surface rules will use
them most effectively. Apparent anomalies and mistakes will become less
puzzling as well.
NLP-Based Technologies
By examining meaning
instead of just matching strings of words, NLP systems can solve many retrieval
problems intelligently. These include identifying concepts, even if different
terms are used to describe the same idea. NLP systems should identify the
names of people, places, or things in any form. The systems could also
encompass speech processing, summarizing documents, and even groups of
documents, and automatically indexing and classifying documents. Each of
these aspects represents a distinct area of research with tools in development
or, in some cases, already on the market.
Concept Extraction and Mapping
Concept mapping
is the key to many new technologies on the horizon. Language provides rich
alternatives in how an idea is expressed. Not only are there direct synonyms,
but metaphors, similes, and other literary devices. These devices delight
the reader, but puzzle the computer. We need systems that can use all those
levels of language to interpret meaning correctly and to relate similar
expressions of an idea to the same concept.
Concept mapping enables us to:
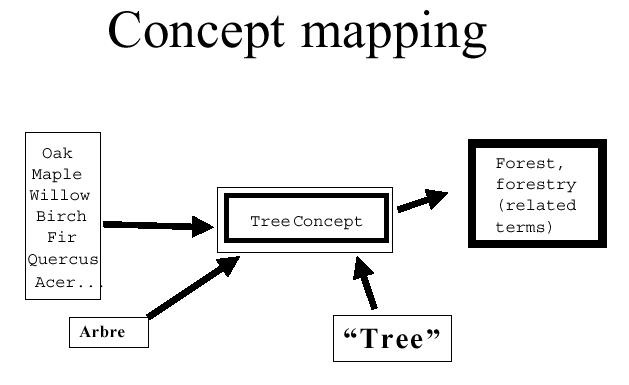
Vocabulary mapping,
a form of this technique, enables a searcher using MESH terms in MEDLINE
to search intelligently in CINAHL, another medical database with a different
thesaurus in control. Thus, the idea of tree has multiple terms mapped
to it, as shown below in Figure 3.
This is a technology
already in place with varying degrees of sophistication. It is used in
the following areas.
Machine-Aided and Automatic
Indexing
Machine-aided
or automatic indexing (MAI) finds major concepts in texts, maps them to
an internal thesaurus or controlled vocabulary, and applies indexing terms
automatically. It may also extract important names, disambiguate words,
and identify new terminology for indexers to add to the system. MAI offers
candidate terms to indexers for their approval. Automatic indexing applies
these terms with no human intervention.
Machine-aided indexing has been around a long time. Most such systems are rule-based and assign terms based on rules such as use automobile as an indexing term whenever a document is about cars, just as professional human indexers do. Data Harmony/Access Innovations is well known for its rule-based machine-aided indexing systems. Northern Light uses rules developed by human indexers to automatically assign broad terms to all documents for its custom folders. Autonomy uses machine learning to automatically categorize materials, and Semio creates taxonomies or hierarchies automatically. Systems such as DR-LINK, developed by Dr. Elizabeth Liddy at Syracuse University, assign subject codes in order to disambiguate words. Some MAI systems work with up to 80 percent accuracy, which compares favorably with manual indexing.
Some experimental approaches use probability and statistics to categorize materials. Muscat, now owned by Dialog, is a good example of this approach. Others are experimenting with neural networks for automatic classification.
MAI systems can also extract important names from the text or disambiguate terms. Consider the term bank. It may be a place to store money, the side of a river, a turn made by an airplane, or the slope of a curve on a highway or railroad. Increasingly Web and other search engines use automatic indexing to disambiguate or to create broad categories for browsing.
MAI can speed up
the indexing and abstracting process needed to prepare databases. It particularly
helps in handling such high volume tasks as assigning metadata terms to
Web documents.
Automatic Summarization
Not too long ago,
no one could find information. Now there is too much of it. Any tool that
gets us quickly to the most important bits is valuable. Quick, automatically
produced summaries have this potential. There are two kinds of automatic
summarization. The first summarizes whole documents, either by extracting
important sentences or by rephrasing and shortening the original text.
Most summarization tools currently under development extract key passages
or topic sentences, rather than rephrasing the document. Rephrasing is
a much more difficult task.
The second process
summarizes across multiple documents. Cross-document summarization is harder,
but potentially more valuable. It will increase the value of alerting services
by condensing retrieved information into smaller, more manageable reports.
Cross-document summarization will allow us to deliver very brief overviews
of new developments to busy clients. We can expect some tools to do this
within the next 2-4 years.
Cross-Language Retrieval
Research communities
now span the globe. Researchers need to know what goes on in their fields
no matter what the language of the source, e.g., companies going global
in scope and interest. Two approaches are in development. The first translates
text from one language to another. The second maps words in the same language
to a single coded concept, just as concept mapping does. Even rough wording
or poor translation is adequate for cross-language retrieval. We can also
use it for retrieving foreign language documents, even if we cant translate
the documents perfectly. The combination of concept mapping and automatic
summarization can deliver a rough gloss or overview of an article so that
a researcher can decide whether to read an entire document.
Entity Extraction
Entities are names
of people, places, or things. As we all know, entities are often difficult
to locate within a collection of documents because many variant terms may
refer to the same person. For instance, AT&T may also be found as
AT and T, or AT&T. Marcia Bates may appear as Bates, M or Bates,
Marcia, but should not be confused with Mary Ellen Bates. President
Clinton was once Governor Clinton and still is Bill
Clinton and William
Jefferson Clinton, not to mention the President.
Newer information
systems develop lists of name variants so that all the forms of a name
map to the same concept and will retrieve all the records, no matter which
term appears in a query. These systems may also contain built-in lexicons
with specialized terms and geographic name expansions, e.g., to include
France when the searcher asks for Europe. System administrators should
have access to the lexicons to add internal thesauri and vocabulary. They
should also add new names or terms as they occur in new materials. NetOwl
is one example of a product that extracts entities. For decades, LEXIS-NEXIS
has used name variants in order to improve retrieval, but automated extraction
and storage give this policy far more power.
Relationship Extraction
With extracted
entities in hand, one can perform some interesting analyses across documents.
For instance, one could find out who has met with whom over the time period
of the collection. This kind of data analysis requires that the system
extract relationships among entities. Some systems can extract more than
60 different types of relationships, including some that describe time
or tense and numbers. Natural language researchers have developed categories
to describe these relationships. For instance:
As we have seen,
words by themselves often do not suffice to establish meaning. If one can
store the context, the syntax, and the unambiguous meaning of each sentence
as a unit, one can build a good question-answering system. Tools like this
can answer questions such as, Who fired the president of Consolidated
Widget Company?
Chronological and Numeric
Extractions
If a system can
determine when and what event has happened, or how large something is compared
to something else, then it can answer questions such as, When was Netscape
bought by AOL? or,Find all the Widget companies that produce more than
5 million widgets a year. With this kind of information extracted from
its contents, the system can also construct chronologies of events. This
may not seem earth shaking, since one might find a biography of a person
instead of constructing one, but imagine the possibilities if the system
could reconstruct the development of a competitor and then use that model
to monitor news for emerging competitors before you have identified them.
Text Mining
Text-mining technologies
differ from searching because they find facts and patterns within a database.
In other words, text mining looks at the whole database, not just a single
document, and then extracts information from all the pertinent documents
in order to reveal patterns over time or within a subject. These technologies
perform some analysis on text in a database to present patterns, chronologies,
or relationships to the user.
Librarians do
data mining almost implicitly to them, information falls into patterns,
groups, clusters, and hierarchies. While it may seem second nature to us,
in fact, it is a rare talent. How can software accomplish the same thing?
Well, it cant with any intelligence. But remember that language is made
up of patterns; this fact lets us generate new, but still understandable,
sentences. If you identify the clues that tell you, for instance, that
something is a prediction, then the software can follow those same rules
to find predictions, e.g., using terms like by next year, in 2010.
Good text mining depends on the quality of the knowledge base on which
it operates. If relationships, concepts, chronological information, and
entities have already been extracted, then the text-mining process can
take advantage of this information and seek patterns within it.
Question-Answering Systems
We often lose
sight of the purpose of information retrieval, which is usually to answer
questions, not just retrieve documents. Question-answering systems look
within documents or knowledge bases to find answers. For example, if you
ask a question-answering system, When was the Wye River Accord signed?,
you will get an answer of October 1998, rather than a list of documents
about the Wye River Accord, which may or may not contain the answer. Question-answering
systems find the best matching answers extracted from within matching documents.
If users need more information, they can link to the source documents.
Filtering, Monitoring, or
Alerting
The difference
between filtering and ad-hoc searching is that in searching, the search
may change, but the database remains the same, while in filtering, the
search stays the same, but the data against which the search matches changes.
Filtering only looks for new documents of interest. To set up a filter,
the user creates a profile or standing query, which runs against any
new additions to the database. The art of designing a standing query lies
in creating a broad enough query to prevent the omission of important developments,
while making it narrow enough to prevent too much information from flooding
the user.
Like any other search technology, filtering or alerting depends on the quality of the search engine used. A search engine that can provide well-focused retrieval, preferably using some sort of disambiguation and concept extraction, will most likely catch related topics.
One of the major
problems with any kind of standing, continuing query, or monitoring service
is that the terminology in any field changes over time. So do a users
interests. Yet, most of todays alerting services are static. Those who
rely on profiles must make sure to update them regularly. As an example,
my own 3-year-old alert on information retrieval returns very little
of interest these days. Instead, I need to add search engines, data mining,
text mining, filtering and routing, natural language processing, knowledge
management, and many other new terms. Newer systems that incorporate some
kind of machine learning or intelligent agents are vital for good continuing
monitoring of topics. Filtering tools that incorporate machine learning
can detect new terms and offer to add them to a standing query. They can
also note changes in the users interests and adapt the query to fit these
new topics.
Change Monitoring
Change monitoring
is a specialized type of filtering. It monitors established documents or
Web sites and determines when changes have occurred within them. The technique
has become a vital part of competitive intelligence or events monitoring.
If a competitors Web site remains unchanged, the system ignores it, but
it raises a red flag if substantial changes and additions occur. Similarly,
official agencies charged with collecting and archiving government documents
need to know when a new revision of a form or document or law appears.
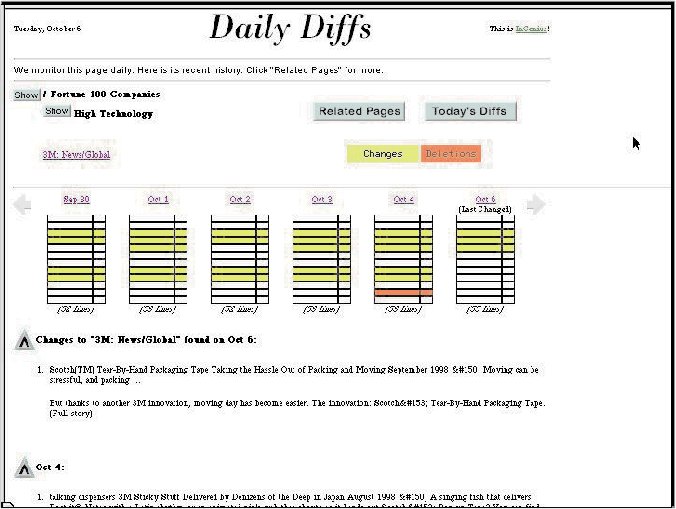
One company that monitors Web pages for changes is Ingenius Technologies [http://www.ingetech.com]. Their JavElink monitors a list of URLs supplied by the client and reports only the changes. The visual display makes it easy to note what has changed at a glance (see Figure 4). Ingenius also uses this technology to create e-mailed alerts [NetBrief, http://www.netbrief.com] that contain only the changed text of a site. The Ingenius site displays several free alerts on popular topics as examples.
A new extension
of NetBrief sends a daily e-mail containing URLs and brief excerpts matching
client keywords. Each day, InGenius reviews 100 online daily newspapers,
as well as dozens of business and technical publications. Clients may add
new sites or search engines as they wish. They may also specifically include
or exclude certain sources or topics.
Visualization
The human eye
understands visual representations much faster than it can read text. As
the old proverb says, One picture is worth a thousand words. Compare
the simplicity and speed of recognizing a picture of people sitting under
a tree at a picnic to reading a description of the same scene. In order
to help people interpret large sets of data or documents, many researchers
are designing visual equivalents of the text, so users can digest the information
at a glance.
Visualization helps handle information overload. Imagine being able to hand a one-page visual overview of the weeks developments to the CEO of a company instead of a five-page digest. Visual information systems are also vital to crisis management, air traffic control, and other situations in which people must respond instantly to a great deal of information.
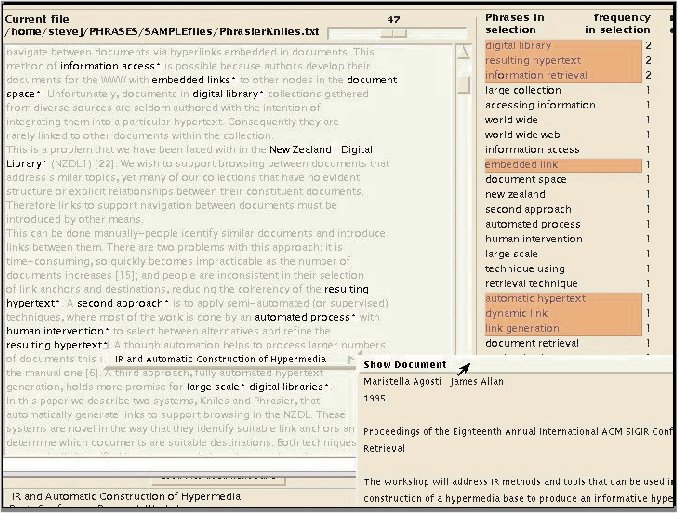
Effective visual representations are confined by the limitations of the computer screen. There is only so much information that can be displayed effectively on the standard 14- or 15-inch monitor. For an example of a nice kind of interface to have, see a description of the interface to Phrasier [http://www.cs.waikato.ac.nz/~stevej/Research/Phrasier], an innovative system for browsing by phrases. The screen design for this product is too large to fit a standard screen, but it contains all the elements that a user would want to have in order to interact well with an information system. It displays documents, related concepts, and key phrases, all in one place. Figure 5 shows part of the screen.
Most of the visual presentations of information we see today are experimental. We really dont know how people will interact with them. Cognitive psychologists, online experts, and computer scientists need more than the anecdotal information we get from usability tests in order to establish guidelines for good design. We do know that people have many different cognitive styles and that to interact with computers efficiently they need tools and interfaces that fit how they think. The great challenge will be to discover how the mind works and then to design tools based on this knowledge.
Some concepts are fairly simple to visualize effectively. Bar charts or even differently sized squares can illustrate quickly comparative sizes, amounts, or numbers. Timelines can show time-dependent events. Proximity of objects can indicate close relationships. Pie charts show how the parts make up a whole. When we move from these common concepts to representing relationships among people and places over time, then we must invent new imaging.
A visualization sits on top of the information retrieved from a system. While the interface determines how the information displays, what it displays depends on the data extracted. Thus, relevance rankings easily display as bar charts. The amount of information available on a topic can show as a set of colored boxes of various sizes.
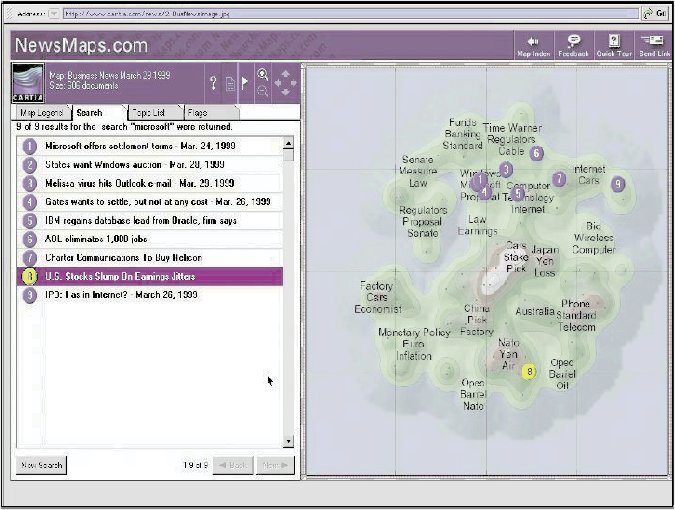
The vector space model that we discussed earlier lies under most visualizations of subject content. It can create star charts, showing clusters of documents, or the imaginary landform maps from Cartia]. Look at this visualization of a set of search results from Cartia in Figure 6. The highest peaks represent subjects having the most documents. The closeness of hills shows proximity.
The browser from the Human Computer Interaction Laboratory [HCIL, http://www.cs.umd.edu/hcil/ndl/ndldemo/draft11/daveloc4.html] at the University of Maryland gives an instant overview of the Library of Congress collections. As you pass your mouse over each timeline, it turns blue, and so do the types of collections that contain information about that time period.
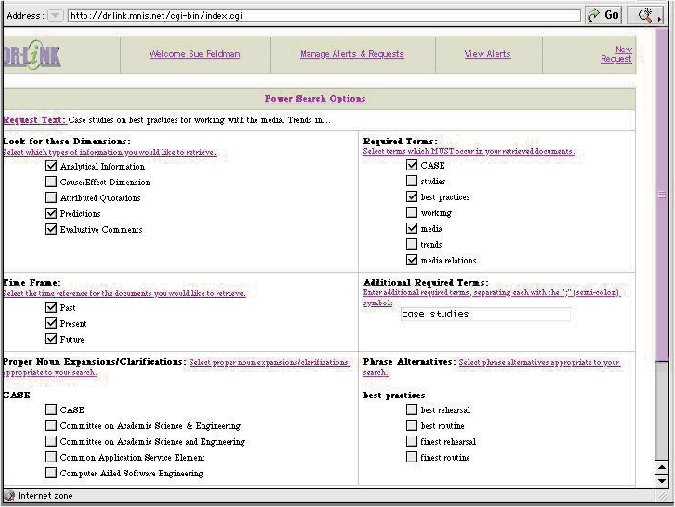
Query formulation is one of the weakest spots in the information process. Several companies and research groups have developed visual aids to query formulation, but I still like the text power search screen from DR-LINK, developed by Dr. Liddy at Syracuse University, that shows you how the computer has interpreted your search and gives you a chance to change it (see Figure 7).
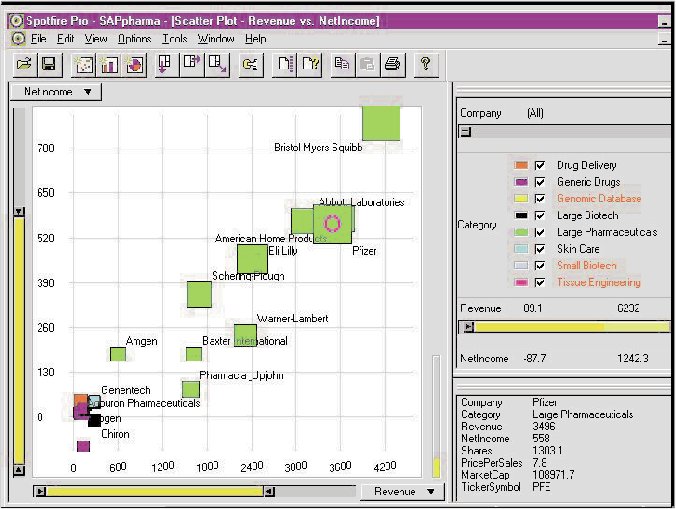
Spotfire (see Figure
8) and Dotfire, its newest form, are dynamic query tools. These
tools present a set of categories that help to narrow down a search. You
can manipulate each category using a slider. HCIL at the University of
Maryland developed both of them [http://www.cs.umd.edu/hcil].
Dotfire [http://www.cs.umd.edu/hcil/west-legal/dotfire.gif]
is the new Westlaw case law explorer. [For more information, read the technical
paper by Ben Shneiderman, David Feldman, and Anne Rose, Visualizing Digital
Library Search Results with Categorical and Hierarchical Axes, CS-TR-3992,
UMIACS-TR-99-12, February 1999, ftp://ftp.cs.umd.edu/pub/
hcil/Reports-Abstracts-Bibliography/99-03html/99-03.html.]
Figure 9 above shows the Hyperbolic browser from Xerox PARC, developed to help people explore the contents of a database visually. You can find it at the InXight database [http://www.inxight.com].
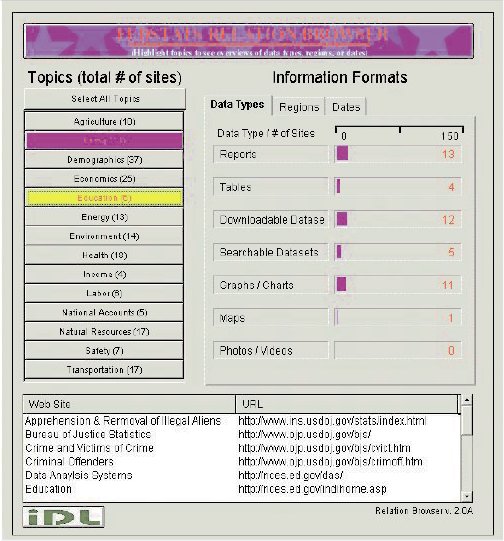
Gary Marchionini and his students at the at the Interaction Design Lab at the University of North Carolina study the effectiveness of interface designs for various kinds of resource formats, such as statistics or video files. The interactive statistical relation browser is a prototype developed for the Bureau of Labor Statistics. It displays, in one screen, subjects covered by the database, the number and format types for reports, as well as regions and dates covered. Related Web sites also display. It is simple, but effective. [See http://ils.unc.edu/idl/ for other research by this group.]
The Perspecta interface shows the user, in one screen, which parameters they can search. This screen shot also shows the results of a search done on their travel information database. Each box shows the user, at a glance, the number of tours that exist in each of the categories requested during the time period indicated. For instance, 87 canoeing tours are offered during a specific time. By grouping results into logical bundles, this software enables the user to understand the results of a search before beginning to plow through the actual hits.
Having tools that can give you several views of the same data helps you discover patterns.
Northern Lights custom folders give you a quick visual overview of search results. The careful categorization of contents makes searching Northern Light both broad and well focused. Northern Light also searches Yahoo! directory pages. Yahoo! has some excellent resources, but I prefer to search rather than to start with a browse. Northern Light gives me the best of both approaches.
I like the simple
display from TASC, (http://www.tir.tasc.com/Visualization/).
TextOre shows the extent of the information about a subject by the size
of the colored squares. If you click on a square, you will see the documents
that it represents, or, for large document sets, further charts. This is
visual data mining.
| WHAT EXACTLY
DO WE MEAN BY MEANING?
People extract meaning from text on many levels:
onlinemag/OL1999/feldman5.htm, Online, May 1999.] |
Tools to Analyze and Interact
with Data
Finding and using
information should be an active process. We need to read what we find,
but we also need to merge sources, pull them apart, separate the data into
categories, sort the data, seek patterns, and send the information to colleagues
and clients.
Puffin Search [http://www.puffinware.com] invites this kind of interaction. It searches across up to eight Web search engines at a time and brings the results back to your desktop. It saves the search results, creating a list of all the terms that appear in two or more citations. Then you can sort, cluster, and re-sort the results using any cell in the table as a basis for comparison. Choose a title and it will re-rank all other hits by their similarity to that title. Or, choose several of the keywords and rank all 1,200 hits by the terms you have chosen. You can sort by search engine or by URL. Puffin automatically forms clusters based on the similarity of a group of documents, using a similar technique to the vector space model. You can also update a search automatically when you use it as a filtering tool.
Netbook, developed
by the Human Computer Interaction Group at Cornell University [http://www.hci.cornell.edu],
is part of a multimedia tools suite that foreshadows what the digital library
will look like in the future. These are the tools that users will demand
as we move to dynamic use of information [http://www.hci.cornell.edu/
projects/projs/multimedia.htm]:
Searching Multiple Sources
Simultaneously
Searching across
different kinds of information collections poses one of the biggest challenges
facing digital library and intranet builders. Collections may encompass
text or images or statistics. Text files may contain bibliographic records,
abstracts, or full text. Image collections may only offer search engines
the text appearing as captions. Once we move outside of controlled, integrated
collections of the same kind of materials, we encounter several obstacles.
These include vocabulary differences, differences in type of materials,
and differences in relevance-ranking algorithms.
Differences in vocabulary are a familiar problem to any experienced searcher. Each collection or source may use different terms to express the same idea. We professional searchers traditionally handle this problem by using every synonym we can think of. Thus, we might choose both pumps and impellers, or theater and theatre to round out a good query. In NLP systems, concept matching may perform some of this work for us. However, customized intranets may want to develop internal lexicons that would map pumps and impellers to the same concept automatically. This is a good application for concept monitoring and automatic indexing.
Searching across heterogeneous materials presents a knottier problem, as searchers working with Dialog OneSearches can tell you. For instance, the weight of each word in a bibliographic record is probably enormously high compared to the same term appearing in a full-text, 10-page document. One could imagine trying to tweak a search system each time it adds a new kind of collection.
Searching across several systems complicates matters still further. Most search engines calculate the relevancy of a document by counting the number of occurrences of each query term in each document. The more occurrences, the more relevant the document. This works fine when the documents are approximately equivalent in length and of the same type. When we combine these materials in a single search, the results will skew by length of text.
If we try to search across search systems, as Web metasearch engines do, we find that each one measures relevance differently. In addition, since each system computes the relevance of a document to a query in part by finding out how rarely that term occurs in the database as a whole, and each collection contains different materials, it is unlikely that what is highly relevant in one collection will rank the same way in another. Data fusion is a set of techniques for establishing a common ground to measure relevance. The lack of data fusion treatment explains why searching across files in Dialog or metasearching on the Web doesnt work well within relevance-ranking systems.
Heres an example. Suppose that we decide to search for a few good articles on the causes of high blood pressure. We pick two Web search engines. But, we dont know that Search Engine 1 covers all the major medical information sites, while Search Engine 2 concentrates on sports. Search Engine 1 finds 250,000 articles about high blood pressure. It ranks them. Search Engine 2 finds 10 articles, and they have only minimal information on the subject. Think back to our weighting algorithm. If high blood pressure appears rarely in a database, it gets a high weight. So, Search Engine 2 gives all of these documents a 98 percent ranking. Since high blood pressure constitutes a common term in Search Engine 1, it gets a lower weight. If our metasearch engine takes the top 10 from each, we will see all 10 of the Search Engine 2 documents before we ever get to those from Search Engine 1. Yet, the results from Search Engine 1, coming from medical sources, may be vastly superior.
Data fusion tries to merge results from several search systems. One technique takes one document from each in a round-robin approach. Another creates a virtual collection that merges all the documents found in all the databases. Then weights are reassigned based on this common collection.
The second technique
gives better results, but is computationally more costly.
Evidence Combination
Evidence combination
improves retrieval from the same collection by using different retrieval
techniques. It will be a hot topic in the next few years, as computing
power increases still further. Any retrieval technique is faulty and will
omit some relevant documents, perhaps due to a poor query, to differences
in terminology, or even to errors in spelling introduced by optical character
recognition programs. Searchers may also miss important documents if the
documents do not appear in the top 30 or 50 examined. Certain ranking algorithms
clearly do a better job on one type of document or another. Some may adjust
for word position or proximity of query terms. Others are partial to long
or short documents or tend to give priority to term frequency instead of
to term rarity in the database. Some may emphasize metadata; others ignore
controlled vocabulary terms entirely. These are all reasonable design choices
that may conform to a particular type of collection. While searchers cannot
always understand why one search engine misses certain documents that another
retrieves, we know that this happens. The differences in search algorithms
may offer one explanation.
Evidence combination
can refer to searching the same collection with different search engines
and combining the results, or it can refer to using different sources to
gather information about documents. For example, a collection of newscasts
might be searched from speech text created by speech-recognition software.
Closed-caption broadcasts would supply another source, and so would the
video images themselves using image-recognition software. Each one of these
sources is not a reliable source by itself none of them contains enough
accurate information on the subject of the document but combined, the
strengths of one make up for the weaknesses of another. Informedia [http://www.informedia.cs.cmu.edu/],
one of the first National Digital Library Projects, offers a good example
of this technique.
Speech Recognition for Spoken
Interfaces
Although we have
become reasonably comfortable interacting with the computer by keyboard
and mouse, it is not natural. Our interactions show it. Who would ask a
spoken question with a single word? Yet, the vast majority of queries on
Web search engines are single words. And would we really choose to input
a query with parentheses and truncation symbols, given a simpler alternative?
Spoken interactions are a more normal mode and a voice interface, or VUI
(voice user interface), may solve some of the input problems that designers
face with written or graphic interfaces.
There are two distinct sides to voice recognition: input and output. Speech recognition can go from text to speech or from speech to text (speech synthesis). Both speech recognition and speech generation software must be developed in order to create good VUIs. The easier of these is speech generation. People already can understand computer-generated speech because they already know how to adjust to slight variations in pronunciation or intonation, if only from listening to real people speak. Companies like Cogentex have already created technologies that generate speech from data plus a template. The Montreal weather report uses this product.
Voice recognition is a more difficult proposition. Natural-language processing gets us part of the way to voice-recognition systems, but a few levels of language important in speech make problems in written language. The way we pronounce words has many more variations than we realize. For instance, the c in cat differs from the c in core. Intonation patterns convey meaning by the song that is sung. A declarative sentence versus a question, for instance, is solely distinguished by the notes that the voice uses a falling instead of a rising inflection. Voice recognition also stumbles on regional pronunciation differences, as well as on finding the boundaries between words. We run one word into another and expect our listeners to make the cut between each one. Computers cant manage this as easily. Try saying, Whats to stop me? in a normal tone to see what I mean. Gotcha!
Nevertheless, voice interfaces have begun to appear. MyTalk [http://www.mytalk.com] from General Magic will fetch your e-mail and read it to you on the phone. It uses speech generation software and intelligent agents to read only what you want. You can interact using several hundred commands and, if you forget what to ask, it will give you choices.
Microsoft, with its SAPI standard (Speech Application Programming Interface) Persona Project, and associated Speech Recognition research groups, seems to be creating a successor to Microsoft Bob, which can interpret continuous speech and then generate an answer. Microsoft uses NLP and could apply this software to information retrieval as well. Other major players are Lernout and Hauspie, Dragon Software, IBM, Nuance, Motorola, Unisys, Dialogic, and AT&T.
Most of the research with NLP and speech recognition concentrates on understanding word boundaries and correctly identifying phonemes across diverse speakers and accents. This is a non-trivial task. One solution is to train a system within a small domain, such as answering customer-service questions for one particular company. Another is to train an application to recognize only one users voice. This latter application is in demand for those who cant read a screen or type. In fact, reporters with carpal tunnel syndrome form a growing group of VUI users.
Once we solve the problem of establishing normal speech interaction as a computer interface, our whole mode of operation with computers will change. We will ask our car for directions and have it tell us where to turn next, after it has mapped out our route. In fact, that is available now. We will tell our agent to read us any news on Internet-related subjects while we make the coffee. It will ask us if we want to hear the urgent message from our boss first. And, we will ask for the monthly report to be generated from our statistics and then presented as a PowerPoint presentation, complete with pie charts, without having to remember how to import a chart and resize it.
Its nearly 2001.
Can HAL be far away?
Designing the Answer Machine
Researchers look for information differently from marketing people or executives. This isnt surprising, since they all have different kinds of information needs. Researchers want in-depth information. Marketing people may want facts, statistics, or to keep up with the competition. Executives may want quick overviews and summaries that give them a lot of information at a high level in a capsulized form. Do your users want everything on a topic (high recall) or just the few best nuggets (high precision)? How will they use the information? Do they need 24 hour, 7-day-a-week access from remote locations? What should the system output look like?
First, find out what your users need, want and how they will use the information. Then, design an access system that fits how they think and work. For instance, we have never found a user population that can distinguish between subject headings and keywords. Dont expect that they will learn. Just create a system that doesnt require too much knowledge unrelated to their day jobs.
Create access models subject, author, fields that make sense to your organization, even if this goes against library orthodoxy. If you only have computer science materials, dont expect that the Library of Congress Classification will be useful. Think about why classification schemes were invented and then use something that can help distinguish among the materials.
Last, design the system so that it will give you what you have already specified. Dont get talked out of important features. And dont let fancy bells and whistles that will confuse the users to creep in. Keep it simple. Make sure that it is easy to navigate. Test it and retest it.
I am not necessarily
a fan of all things automatic. The best systems give users an opportunity
to interfere, add information, alter directions, and make corrections.
These systems form a partnership with the user. When designing an information
system, include the user in the design. In the best of all possible worlds,
system designers would observe how people use information within the work
place and then design a system that fits into the normal work flow.
Conclusion
All these technologies
add up to a seamless suite of information tools that will find information,
organize it, keep it up to date, forage for patterns, and present visual
overviews for quick understanding. In other words, an Answer Machine. The
tools I have just described will enable us to understand large and complex
sets of information more easily. These tools enable quick understanding
by adding a new dimension of analysis and even fun to working with information.
They will give knowledge workers the ability to examine, manipulate, and
understand the information we retrieve for them. Using these tools, we
can move up a level of abstraction to analyzing, evaluating, and planning.
This will offer our profession an exciting, challenging role bright with
promise.
To be involved in the development of the next generation of information system, we must be willing to think big, stepping back occasionally from deadlines and from gathering isolated facts and statistics. We must comprehend and clarify the place of information in the organization. This is a role for practical visionaries.
Fortunately for
us, thats exactly who we are.
|
Smith Widgets, Inc., October 5, 1999. 10:00 AM Boss: Good
Morning, Dennis. We need to update our competitive intelligence report
today. Id like to know all the new products our competitors have come
out with in the last 6 months, as well as any plans they have for new products.
Dennis (calling
boss): Hi, I have the product info and sales figures for your three
competitors. Shall I send them to you electronically? There were 467 documents
from the online search, and Ill scan them as fast as I can to get you
the info you need. Im using PuffinSearch to merge and relevance rank the
searches I did in Dialog, NEXIS, and Dow Jones. Is it okay with you if
I just start with the top 150?
OUTCOME: Dennis had to quit, having missed both lunch and dinner, at document 322, in order to have time to write the summaries and bullet points in time. Document 463 showed that Automated Widgets had hired an expert in networked appliances from Sun Microsystems. Smith Widgets was bought out by Automated Widgets in 2003. The Boss took early retirement. Dennis went on to help create a company-wide information system, designing templates for interaction and categories for automatic indexing.
Automated Widget Company, October 5, 2009. 10:00 AM Boss:
Good Morning, Alvin. We need to update our competitive intelligence report
today. Id like to know all the new products our competitors have come
out with in the last 6 months, and any plans they have for new products.
(11:30. Boss walks into room) Boss:
Alvin, is the report ready?
In the people category,
Andrew Wyatt gave a talk in September at the Futuretech conference. I summarized
it for you. You met him at the WIA conference last spring, and I have a
note to tell you to contact him in October. His phone number is 577-304-8976.
His e-mail is aww@futuristics.com. I have his street address, too.
OUTCOME:
Automated Widgets is slugging it out with MS Widgets at the moment. Will
either of them notice Solutions.com sneaking up on them? This is a case
of dueling information systems. Winner take all. Which one has the better
technology for raising red flags? Which do you think?
|
|
The dawn of a new era can be exciting or unsettling. Right now, there are so many fingers in what used to be our information pie that we may feel crowded and, perhaps, threatened. Computer scientists, psychologists, graphic designers, linguists, and Internet businesses are all carving out pieces for themselves. What do we information professionals have to offer of value? First, we have a unique perspective about information itself. We understand how to ask the right questions in order to find what we need. We understand balance in collections, good sources, and how to categorize materials so people can find them. This is invaluable. We also have something the others may lack we use information systems. We have searched for information for decades. We have practical experience. If we can temper the experience with the flexibility to try something new, we can become the part of the development team most firmly anchored in reality. This brings me
to some tentative ideas on what to look for as you go about putting together
an intranet or information system for an organization. These thoughts are
tentative because they havent been tested, and my theories are just as
suspect as anyone elses. I can only rely on my own experience and tests
of technology. Based on my comparisons of NLP systems with other systems,
I know that NLP systems work and work well. Similarly, I have been extremely
pleased with the agent systems and automatic indexing systems with which
I have experimented. So, I know that the foundation technologies work and
much better than anything else Ive tried. I think that if I were putting
together a system for tomorrow, though, that I would look for products
with these technologies as my base.
|
Susan Feldman
is president of Datasearch, and of Datasearch Labs, a usability testing
company for information products. She writes frequently on new information
technologies, and tests, evaluates and recommends products for clients.
Her e-mail address is sef2@cornell.edu.
Copyright, Susan
Feldman. Publication rights and rights to reprint this article and diagrams
are assigned to Information Today, Inc. The author reserves the right to
distribute copies for educational purposes, post the article on the WWW
once it is not available freely, use portions of the text and illustrations
for other purposes, or include the article in future collections.
| Contents | Searcher Home |
![[http://www.cs.umd.edu/hcil/west-legal/dotfire.gif]]([http://www.cs.umd.edu/hcil/west-legal/dotfire.gif]){kind=link}