|
|
The Web generation
demands full text and they want it now. Dont talk about copyright or passwords.
They know its all technologically possible and they want it NOW. Despite
what you read, or what vendors of all shades and stripes want you to believe,
a significant number of our users were still showing up with a piece of
paper with references on it, looking for full articles. So with a Web-enabled
OPAC, a visionary director, a relatively generous serials and online budget,
and the best intentions, we set out to make it happen. This article chronicles
the bumps and boulders in the path we tread and those we foresee on the
road ahead.
The Environment
The Medical Research
Library, established in 1860, has a collection of about 250,000 volumes
and 3,000 serial titles, of which about 1,500 are current subscriptions.
With a staff of about 30, the library serves the medical school, and graduate
faculties in nursing and allied health sciences, as well as affiliated
hospitals. Like many similar institutions, it must equally serve the clinical
physician urgently seeking the answer to a real-life problem as well as
the student and scholarly investigator. The librarys strength has always
been its well-focused serials collection. The librarians are committed
to maintaining the librarys archival and research mission in the
librarys core subject areas.
The library began occupation of its current facility in 1991 and does not yet have serious space concerns, though every library must manage its space effectively for the long term. Following the general trends in serials management, impact factor, usage statistics, and staff and faculty input have been used to pare print subscription lists over the past decade. The staff keeps the collection as tightly focused as possible to satisfy needs and to control the spiraling cost of serials.
One serials agent handles the bulk of the print subscriptions, with two other agents handling smaller orders for government documents and standing orders. Some few titles are handled directly with the publisher. The library also had subscriptions to several database aggregators that covered core literature and beyond, many of them offering a high number of full-text articles. These services had always been presented to users as separate and distinct from our permanent collection. But the educational services librarians decided to instruct users in how to find full-text articles by navigating through these databases. In the past, the Reference and ILL staff usually had employed the databases to fulfill user requests for help in locating particular articles.
Professional staffing
in Technical Services was very lean, consisting of one cataloger/serials
librarian, two library assistants, and a manager also responsible for collection
development and acquisitions, as well as participation in upper-management
decision-making. With the permanent staff stretched so thin, the director
wisely chose to add a library management consultant as the project manager.
Attitude Toward Technology
The director and
his professional staff embraced technological advances early. Their Web-based
OPAC has been operational since the mid-1990s. They are equally ready to
employ electronic serials to meet the needs of present and future users.
While remaining committed to an archival print collection of core titles,
including binding of those titles on a regular basis, the professional
staff yearns to embrace electronic serials as both a substitute when they
meet all the needs of a research collection or as a supplemental, easily
accessible format. The hard facts remain that only a relatively small percentage
of core titles are yet available electronically in a consistently appropriate
format and as a reliable archive of a reasonable size.
Goals
We had several
goals for the project. Our overriding mission was to get as many full-text
titles in our core subject areas to users via the librarys Web site as
possible and with as little hassle and additional cost as feasible. Reasons
for attempting this were many. Renewal dates for our print and companion
electronic subscriptions were looming right ahead of us. Years of usage
analysis and weeding decisions had pared down the historical research collection
of print serials already, but we hoped to eliminate even more print titles
by finding titles we got electronically from other sources. Decision deadlines
for licenses to OCLCs FirstSearch and ECO, Ovid, LEXIS-NEXIS, and Gale
Groups InfoTrac were also nearing.
To achieve our goals, we set three objectives. First, we wanted to analyze our current subscriptions against electronic offerings. Second, we had to actually make the electronic subscriptions work. Third, we needed to put a system in place to manage all subscriptions wed selected, both print and electronic, in the future. To do all this we knew we had to develop a methodology for analyzing the sources, costs, and difficulty of obtaining the titles, whether in print or electronic format, and to do it quicklyremember those pending renewals.
Throughout the
project, we vowed to remember the user. Questions that serials literature
can answer typically come in two forms. One is a subject approach, increasingly
well-satisfied through the aggregators of online databases that carry ever-increasing
amounts of full text. The other, still very common, approach is searching
by journal citation. Physicians and students still arrive daily with citations
scrawled on scraps of papercitations jotted down from an article they
read or heard mentioned verbally or by e-mail from a colleague. We intended
to build a system of electronic serials that could satisfy both these two
approaches.
Integrated Library System?
Hah!
Immediately we
discovered that our so-called integrated library management system could
not handle this project. It was far too inflexible in a variety of ways.
For several reasons, we could not use the acquisitions module of the librarys integrated library system for subscriptions. The library had made a cost-effective contract with our primary serials agent that specializes in health sciences materials. We were satisfied with the service in many important areas, but the agents were not particularly progressive technologically. Though other subscription agents already had interfaces that enabled their customers to download the agents lists of titles directly into ILS programs, ours did not. When queried we found the agents had no plans for EDI in the foreseeable future. Since there was a limitation to the number of items that we could enter on a purchase order in our system, a subscription order of over 1,000 titles would have overwhelmed a small staff, not to mention created the need to re-enter and verify all that entered data against a master printed list each year.
The complexity
of the ILSs ad hoc reporting capabilities also precluded running the reports
that conceivably would make all that data entry worthwhile. Unfortunately,
this was a case whereby automating subscription purchasing within our existing
ILS would have been more trouble than it was worth. Exploring the catalog
module for a solution to our serial management needs, we quickly realized
that our basic MARC bibliographic records were no place to start putting
acquisitions information. Though our database certainly contained our 1,800
current print serial titles, that was the least of our needs. For starters,
we couldnt enhance that database to incorporate our online vendors journal
lists without seriously compromising our OPAC. We could catalog our electronic
serials, but we couldnt check them in. Our system would have forced
us to enter a mandatory barcode for each of these electronic issues, or
it would look to users as if we had never received issues. Would we enter
the vendors archive as our holdings? How difficult would that be to keep
accurate? We might have exported our own current serials list from our
ILS through customized programming from our ILS vendor, but we couldnt
handle the price tag. So without further consideration we turned once again
to our PCs and our Web site for salvation.
Stage One: A Spreadsheet
First we developed
a set of spreadsheets based on journal lists we had received from our serial
agents and the database vendors. We requested an electronic file in spreadsheet
format from the vendors. Sometimes they complied; sometimes they didnt.
Surprisingly in this era of licensed sales of full-text collections, none
of our vendors seemed prepared for such a request. Usually it took several
referrals within the company before we got to a person who could send the
electronic file or even a paper list.
With the vendor lists in hand, we keyed in what additional information we needed.
We set up separate spreadsheets with at least three columns: the journal title in the first column, the vendor name in the second, the publisher in the third, and notes in a fourth. We imported files whenever we could and keyed in the rest. If we didnt have data for a particular cell, we left it blank. If an electronic file had extra data, such as price or online availability, we made extra columns to accommodate those data elements. Next we merged these spreadsheets into one big one, then re-sorted it by title. With inconsistencies in the form of entry for titles taken from different lists, we had a bit of cleanup and checking to do to make the lists sufficiently accurate.
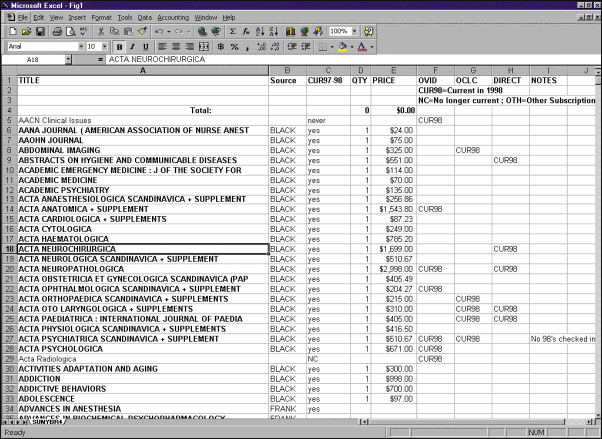 The
master spreadsheet now had all the occurrences of a single title together,
letting us detect where we had multiple electronic sources for a single
title [see Figure 1. Sample of Spreadsheet].
With this master spreadsheet in hand, we could finally see how much overlap
existed between online databases and our own print and electronic collections.
At this point, we had to take our primary serial agents word for it that
we had active subscriptions to electronic versions of our print journals,
since we had not yet tried to access any of them. (Something we would later
come to realize was a real leap of faith.) At this stage, however, we only
noted when we had the title available to us directly from the publisher.
The
master spreadsheet now had all the occurrences of a single title together,
letting us detect where we had multiple electronic sources for a single
title [see Figure 1. Sample of Spreadsheet].
With this master spreadsheet in hand, we could finally see how much overlap
existed between online databases and our own print and electronic collections.
At this point, we had to take our primary serial agents word for it that
we had active subscriptions to electronic versions of our print journals,
since we had not yet tried to access any of them. (Something we would later
come to realize was a real leap of faith.) At this stage, however, we only
noted when we had the title available to us directly from the publisher.
This spreadsheet
did enable us to sort and re-sort our data based on title and online vendor
and make some more intelligent decisions about database licensing. To our
astonishment, we discovered much less overlap among databases than our
personal experience and intuition had led us to believe would be the case.
Stage Two: A Database
 Next
we moved the data into a relational database program, so we could begin
to build a system which would at least last through the galloping changes
over the next few years in pricing and availability of full-text journals
online. We divided the database into two parts. The main database contains
the print titles, and the secondary database has the online titles [see
Figure
2. Primary Database, and Figure 3.
Secondary Database]. If the online title is available to us from more than
one source, we listed them all. We enhanced our database by adding ISSNs
as needed to avoid confusion. We standardized the title entries strictly
as the entries became our key field for linking to the secondary database
of online subscriptions. We also added fields for publisher in the main
database and an indicator of online journal availability. In the secondary
online database, we added details on host, file, and publisher, as well
as a note field for detailed instructions on how to access journals coming
directly from the publishers. We set up paper files for each publisher
of electronic serials to facilitate following and fully documenting the
often complex administration and agreements required. We created some reports
and printed them out for distribution to other library staff.
Next
we moved the data into a relational database program, so we could begin
to build a system which would at least last through the galloping changes
over the next few years in pricing and availability of full-text journals
online. We divided the database into two parts. The main database contains
the print titles, and the secondary database has the online titles [see
Figure
2. Primary Database, and Figure 3.
Secondary Database]. If the online title is available to us from more than
one source, we listed them all. We enhanced our database by adding ISSNs
as needed to avoid confusion. We standardized the title entries strictly
as the entries became our key field for linking to the secondary database
of online subscriptions. We also added fields for publisher in the main
database and an indicator of online journal availability. In the secondary
online database, we added details on host, file, and publisher, as well
as a note field for detailed instructions on how to access journals coming
directly from the publishers. We set up paper files for each publisher
of electronic serials to facilitate following and fully documenting the
often complex administration and agreements required. We created some reports
and printed them out for distribution to other library staff.
Stage Three: Actually Using
It
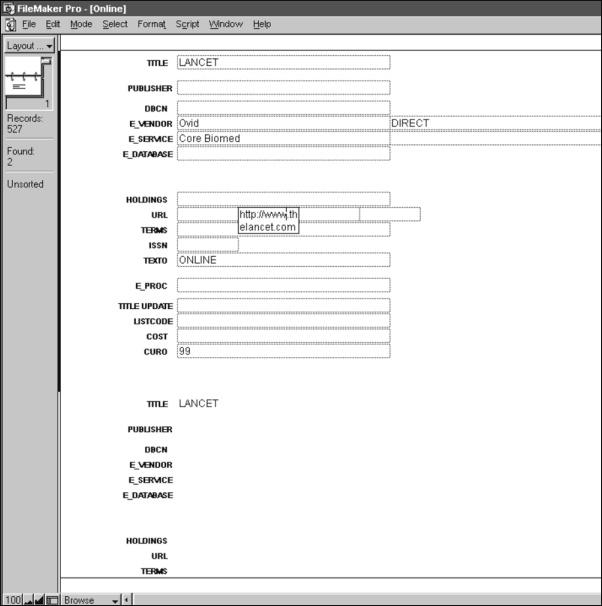 After
untold hours of database cleanup by a dedicated part-timer, we had the
database in pretty good shape. We began the quest to actually gain access
to the electronic titles we had subscribed to and to facilitate their location
by our users. While we would have preferred our Web-based OPAC catalog
to indicate the location of our full-text journals online, it would not
enable us to effect a hyperlink to that text. So we opted for an interim
strategy, with the word interim signifying that we still hoped to one
day link directly from our integrated catalog. Though we could have mounted
our FilemakerPro files on the Web site as a searchable database, this would
have required more time and additional software. Hence, we opted for the
quickly executed method of mounting an HTML list in alphabetical order
of our titles, with hyperlinks to the online sources whenever possible,
or at least information about where the titles could be found. This is
a fairly typical way of presenting journal and other long lists on the
Web when the primary access point is title. It provided a quick look-up
source that soon became heavily used. We added our print holdings to this
list (by typing them in), though our wonderful OPAC already has them on
file, just to avoid forcing users into a second step search whenever possible.
After
untold hours of database cleanup by a dedicated part-timer, we had the
database in pretty good shape. We began the quest to actually gain access
to the electronic titles we had subscribed to and to facilitate their location
by our users. While we would have preferred our Web-based OPAC catalog
to indicate the location of our full-text journals online, it would not
enable us to effect a hyperlink to that text. So we opted for an interim
strategy, with the word interim signifying that we still hoped to one
day link directly from our integrated catalog. Though we could have mounted
our FilemakerPro files on the Web site as a searchable database, this would
have required more time and additional software. Hence, we opted for the
quickly executed method of mounting an HTML list in alphabetical order
of our titles, with hyperlinks to the online sources whenever possible,
or at least information about where the titles could be found. This is
a fairly typical way of presenting journal and other long lists on the
Web when the primary access point is title. It provided a quick look-up
source that soon became heavily used. We added our print holdings to this
list (by typing them in), though our wonderful OPAC already has them on
file, just to avoid forcing users into a second step search whenever possible.
Stage Four: Attacking the
Publishers One by One
Now we had our
list of journals available on site either in print or in full text online
through our licensed databases. But so far we hadnt really done anything
to enable our direct electronic subscriptions. We needed publisher lists
so we could work with each individual publisher to create access for our
users. We embarked on the task of getting the access set up with more enthusiasm
than our publishers showed. To our dismay it proved a time-consuming and
sometimes unrewarding task.
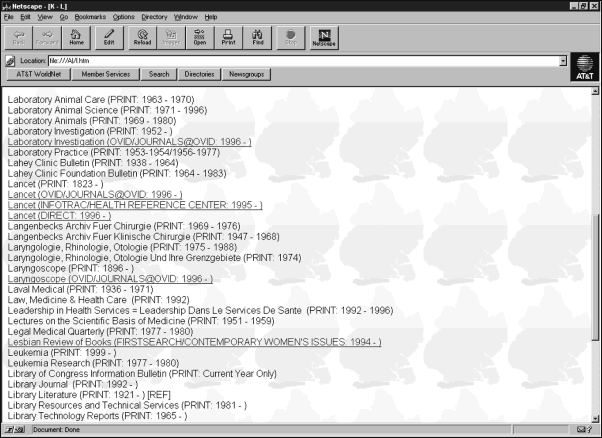 Each
publisher had a different system and procedure. Some provided access based
on IP address; some could only provide individual password access. Some
had to enable our electronic access to their Web site; some used third-party
online publishers with their own set of registration protocols. Some registration
was done online, but didnt always work; some was done by phone or fax.
Worst of all, it was often difficult to find the right contact person at
the publisher who could even explain to us what they offered or what they
needed from us. Slowly but surely, we did manage to create pathways from
our site for our patrons. The list of online full-text sources with hyperlinks
to publisher sites has grown [see Figure 4.
Sample of HTML list].
Each
publisher had a different system and procedure. Some provided access based
on IP address; some could only provide individual password access. Some
had to enable our electronic access to their Web site; some used third-party
online publishers with their own set of registration protocols. Some registration
was done online, but didnt always work; some was done by phone or fax.
Worst of all, it was often difficult to find the right contact person at
the publisher who could even explain to us what they offered or what they
needed from us. Slowly but surely, we did manage to create pathways from
our site for our patrons. The list of online full-text sources with hyperlinks
to publisher sites has grown [see Figure 4.
Sample of HTML list].
Questions of Responsibility:
Agents, Publishers, and Secondary Publishers
We encountered
many problems during the course of this project, but the most devastating
was the quality of the original lists. Online availability as described
by our serial agent was woefully inaccurate, but so were the database vendor
listseven those we downloaded from their Web sites. They were inaccurate
to begin with and hard to keep up with. Agreements between primary and
secondary publishers are changing faster than ever due to the Internet
opportunities. Lists inaccurate in the first place went through constant
changesor should have. Sometimes we were notified, sometimes not. Sometimes
availability of online versions to print subscribers comes as a notice
with an issue. Slips of paper stuck in incoming issues are easy to miss,
particularly by clerical staff with no reason to seek them out. Disregarded
notices mean we miss opportunities to alert our users to new online sources.
Lag times presented another problem. One online vendor fell so far behind in mounting full text of popular titles that users started reporting the lag to the reference librarians. This made us glad we had kept certain publisher-direct electronic subscriptions as back-up for our lagging online database.
Isnt our agent responsible for giving us an accurate list of our electronic subscriptions? We didnt think it was our responsibility to check each publisher directly to verify what exactly we had purchased electronically and to learn how to access it. Yet that is exactly what we had to do for almost all of them. The publishers themselves often had staff working on electronic subscriptions who we had to ferret out despite poor interdepartmental communication. We were asked for our serial agents journal ID number so often during the process, that we began to feel we were doing the agents work. We regretted not having had that ID number in our database to avoid continual look-ups on our serial invoice.
In all fairness, however, the publishers offerings are changing at the speed of light. One minute the subscription is bundled with the print, the next minute its $500 extra. The serials agent would have plenty of trouble keeping up, but at least they would have economies of scale we dont have. For example, you need to register with Catchword, then call the publishers who have titles available through Catchword to enable your access to their titles only. To add to the confusion, some of the publishers use third-party online publishers such as Catchword, necessitating another level of administration we had to take care of on our own.
Database vendors lists were no bettereven those we downloaded from their Web sites. Inaccurate to begin with, the lists are also hard to keep up with. Agreements between primary and secondary publishers change faster than ever due to the Internet opportunities that are perceived. This makes the lists less than accurate and constantly changing. We even found it hard to determine the date of the lists last updating. Comparing old and new lists for deletions and additions could be painstaking.
Some publishers
and aggregators did not understand the continuing need for easy and intuitive
access by known citation. Their online systems are set up in such as way
that the pathway to a known citation follows a Byzantine logic, if any
logic at all.]
| ADVICE
To: Agents, Publishers, Secondary Publishers, and Librarians From: Librarians Everywhere Subject: Service! Service! Service! To Serials Agents: Please fulfill your role as subscription agents, regardless of publication format, or admit that you will only deal with print and take your chances. Dont wait for us to figure it out for you, or our need for your service may dwindle as electronic full-text increases. To Academic Publishers: Remember the library market. It has always been your bread and butter. Understanding the way that both library professionals and end users search and retrieve electronic information will be as important as ever as a result of the information glut we are all experiencing. It seems your Web designers havent understood how libraries really work. Educate them so they can better serve us. To Secondary Publishers: Accurate information about the publications that make up your databases is crucial to libraries and their users. Providing efficient ways to let users know exactly what publications and issues are covered in your databases in a timely way is more than a marketing tool, its good service. To Librarians:
Despite the difficulties, address these questions now or you do a disservice
to your users. Be persistent. Make your needs known to all the vendors
in the subscription chain or you do a disservice to your suppliers. Educate
library staff. Educate library users.
The Future
Our workflow would be more efficient and our Web site journal list more current if we made our database directly searchable to users on our Web site. This is not a pipe dream. Both FilemakerPro and DB/Textworks have Web-enabler programs that can accomplish this with relative ease. This would eliminate the need for preparation of an HTML report from our database for mounting on our Web site and make our updates immediately available to users. On the other hand, dont we have a right to expect our ILS to accommodate these new sources efficiently? Its the same cast of characters: academic libraries and their users, among them scholars/authors, scholarly and commercial publishers, online database publishers, and aggregators. But all our expectations have changed because of the technology. Despite all the full text available online now, full-text suppliers all along the production/distribution chain may want to use the technology to provide better service, but they find themselves seriously threatened or challenged by the new, uncharted economics of publishing on the Web. We found a way to deal with it for now. But we sure didnt like the process. |
| An Alternate Methodology:
Using FSO, BPO, or Net.Journal Directory We initially rejected using one of the commercial directories of full-text online sources, maybe mistakenly judging the vendors themselves as the best sources. There are three directories that we know of that track full-text titles: Fulltext Sources Online, Books and Periodicals Online, and Net.Journal Directory. All are available in electronic versions that we might have used to facilitate the analysis. We could have merged our own serials subscription list with data taken from one of those directories for the online database vendors under consideration. Since vendors lists turned out to be pretty inaccurate, directory publishers probably have the same difficulties in obtaining accurate lists as we did. If they have good quality-control mechanisms in place providing more accurate, current lists of full-text sources, well definitely look to use them for updating our lists in the future. If any of these directories does a better job than the vendors themselves, theyll have our business. Look for a comparison of these sources in a future issue. |
|
|
| Contents | Searcher Home |