REDEFINING SEARCH
Who Knows You Better — Smart Software or Your Significant Other?
by Stephen E. Arnold
In 1996, when Net Perceptions was founded, the field of recommendation systems was largely unknown to those who were interested in the internet. Eight years later, Net Perceptions was liquidated, a casualty of the dot-com bubble and management decisions. The firm’s modern-day impact has been significant. One executive who understood the value of adaptive personalization and the output of the Net Perceptions’ GroupLens recommendation engine was Jeff Bezos, founder of Amazon. After the implosion of Net Perceptions, its former employees found their way to such companies as Google, eBay, and Xerox’s PARC (Palo Alto Research Center).
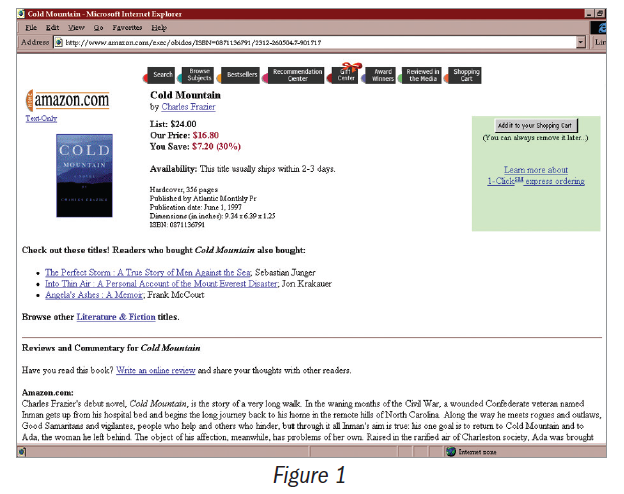
The early implementations were basic. In the late 1990s, Amazon’s recommendations were focused on other books of interest. Net Perceptions’ GroupLens technology produced “Check out these titles!” suggestions. (See Figure 1.) The first system operated with minimal input from the customer. As Amazon’s experience with adaptive personalization and dynamic interfaces grew, users could provide input about suggestions that were not relevant.
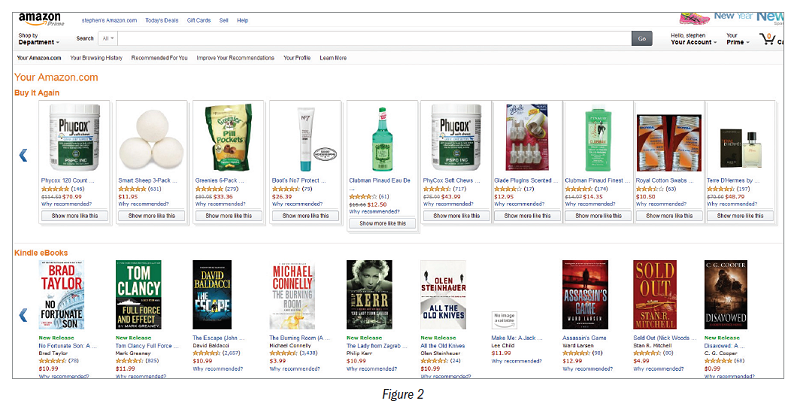
In 2015, Amazon’s expanded recommendations cover the customer’s retail spectrum. Here is what Amazon shows me when I click “Stephen’s Amazon.com.” (See Figure 2.) In addition to the two lines of products displayed, it shows Home and Kitchen products with subrecommendations; for example, “More like FoodSaver Quick Marinator.” Moving through the recommendations requires five page-down actions.
The idea of adapting to user behaviors was a good one. Firefly Network, another early personalization system, was sold to Microsoft in 1998, 3 years after opening for business. Erich Luening, writing for CNET, explained Firefly’s offerings: “Firefly’s flagship product, called Firefly Passport, is used to collect user preferences anonymously, recommend Internet content, and send appropriate advertising. Firefly has stringent privacy policies that are incorporated into its technology. …” Firefly advocated controlled profiling, and it was an early supporter of consumer controls for the personalization service.
Artificial Emotional Intelligence
Fast-forward a couple of decades, and recommendation and personalization systems have entered the mainstream. Advances in a number of enabling technologies have made it possible to perform more sophisticated operations on data generated by user behaviors. “Fusion” technology, available from companies such as Kapow Software (a unit of Kofax, a scanning company), makes it possible to pull data from disparate sources and normalize content for high-speed content analysis.
Smart software finds relationships and formulates conclusions about individual users, the groups to which they belong, and their social content. Facebook, Pinterest, Snapchat, and Twitter are sources of fine-grained information about these users. Employing algorithms that find hidden connections in billions of data points is no longer a hurdle.
Firefly and Net Perceptions provided comparatively basic levels of recommender sophistication. I would describe them as the Model T cars of their era. Today’s systems operate more similar to a Toyota Camry: efficient, reliable, and ideal for the mainstream. In short, there is opportunity for innovation and the application of recommender systems to interface design.
U.K.-based newspaper The Telegraph brought attention to smart software. In the article “Facebook Knows You Better Than Your Members of Your Own Family,” personalization finds itself in the crosshairs of mainstream media. Sarah Knapton, The Telegraph’s science editor, worked through a Cambridge University research study to learn that “[r]esearchers, by analyzing self-reported personality scores for what are known as the ‘big five’ psychological traits— openness, conscientiousness, extroversion, agreeableness, and neuroticism—have created an algorithm which can accurately predict personalities simply based on Facebook interactions. And, surprisingly, it knows your character better than your close friends.”
Tucked in the body of the article is a statement by Wu Youyou of Cambridge’s Psychometrics Center. His comment strikes me as significant: “In the future, computers could be able to infer our psychological traits and react accordingly, leading to the emergence of emotionally-intelligent and socially skilled machines. In this context, the human-computer interactions depicted in science fiction films such as Her seem to be within our reach.”
Smart software informed by artificial intelligence, deep learning, or Facebook algorithms is making significant strides. Systems that know a person better than his or her significant other are part of today’s online environment.
Did You Mean …
Misspellings are irrelevant to Google. The web search giant fixes a spelling error in a query or asks, “Did you mean … ?” and then shows what the human user errantly typed into the search box. For those who are looking for a pizza joint on their mobile phone, the personalization makes finding that information easier and quicker. Bing, Facebook, and Google monitor what each user does and adapt to some degree to that user’s behaviors. The preferences are identified, remembered, and tapped to improve the user experience.
Personalization and marketing are likely to be put into public places as advertisements, such as those in the 2002 film Minority Report, which is based on a Philip K. Dick short story. In the motion picture, ads recognized individuals as they walked through a concourse. The ads spoke directly to the person whom the smart software recognized. Behind the scenes, a query about the person produced a profile. The system then matched the profile to the pool of available advertisements. Voilà! One-to-one messaging, up close and very personal.
San Francisco-based RichRelevance, a company that delivers omnichannel retailing, rolled out a collection of APIs to make it easier for retailers to “integrate personalization into any of their applications.” RichRelevance asserts that it is “#1 in omnichannel personalization.”
The company’s customer list includes Target, Costco, Marks & Spencer, Office Depot, L’Oréal, and Priceminister. It says it “opened its cloud-based platform through its service-oriented architecture (SOA) to accelerate ‘Relevance in Store’—a strategic omnichannel initiative that enables clients to seamlessly merge disparate data sources and build applications that adapt to where, when and how consumers shop today.”
The upside of personalization is that retailers close more deals. Those looking for information can scan a list of prepared outputs, thus saving time. I recall, however, an instance in which personalization added to the stress of one family. Forbes reported in February 2012 that Target’s data mining “discovered” that a teenage customer was pregnant. The personalization system started sending her coupons for baby items. To make a discomfiting story short: Target knew the teen was pregnant before her own father did.
Personalization technology is making inroads into a number of business sectors. Teachers and students will have wider access to “personalized learning.” According to WIRED, the U.S. Department of Education defines personalized learning as “instruction that is paced to learning needs, tailored to learning preferences, and tailored to the specific interests of different learners. In an environment that is fully personalized, the learning objectives and content as well as the method and pace may all vary.”
The interesting question to consider is, “Who makes the decisions about personalization?” With a strong interest in online learning and computer-assisted instruction, the answer is likely to be “technology.” Alexandre Passant, co-founder of Music and Data Geeks, a data science company, highlights how behind-the-scenes adaptive functions have sparked some music industry concerns. The personalization of entertainment is moving forward. Hypebot.com, an online information service that tracks the music sector, sees a natural affinity among “advances in Data Science, wearable, and context-aware computing.” Passant points out:
On the one hand, advances in large-scale infrastructures and AI now make [it] possible to run algorithms on billions of data-points—combining existing techniques such as Collaborative Filtering or Natural Language Processing, as well as new experiments on Deep Learning; On the other hand, social networks such as Twitter or Facebook provide a huge amount of signals to identify user tastes, correlations between artists, trends and pre dictions and more—which could go further [than] dis- covery by creating communities through music-based user profiling.
Some artists may push back against the smart streaming services. Taylor Swift pulled her current hit album from Spotify. She had millions of reasons to do so, because the revenue generated from YouTube views far outstripped the few thousand dollars she received from Spotify. Some consumers may find that the seamless experience of having software present distractions is a welcome shift from the drudgery of finding music they like.
What Is Lost?
Some next-generation information access systems (NGIASs) personalize content for individual users or workgroups. Companies that offer this function include BAE Systems, Leidos, and Recorded Future. The idea is that as the user performs work tasks, the system builds a profile of what he or she does with information. These data points are used to assemble easy-to-digest reports or visuals. For certain types of work, the adaptive system automatically adjusts to help ensure that the user receives needed information that’s directly related to a work task. When the task changes, the system’s outputs adjust automatically. The approach points to the future of search, shifting the burden from a user who must know what information is needed and have mastery of the keywords required to unlock the index. These NGIASs eliminate that hurdle for certain types of knowledge work.
Are there downsides to personalization? Few of my acquaintances are critical of Amazon’s recommendation feature or the Netflix function that suggests other videos for them to watch. Google’s ubiquitous autosuggest feature and its pre-fetching of certain data for mobile users of its services are part of the digital fabric of life in the 21st century.
One of the main considerations for recipients of personalization is privacy. A system and presumably the administrators of that system have access to a wealth of information. Monitoring software, unlike humans, notices everything and forgets nothing. Sophisticated algorithms can relate details in ways humans cannot do without considerable effort. If the data about a person falls into the hands of an unscrupulous system or individual, certain risks loom. Personal behaviors may put a job in jeopardy. A sequence of behavior over time may lead an insurance company to question the appropriateness of a policy for an individual who pays to drive in specialized driving schools.
Also, what degree of control does the individual or a third party have over the information? I know that I unconsciously filter information. I push aside information about certain technologies, preferring to focus on more novel ways to solve a particular problem. When software filters for me, I am removed from the loop. The information arrives already groomed, similar to a Westminster Kennel Club show dog. Once comfortable in a system-filtered data fish tank, I can see myself losing what I think is one of my strengths: recognizing significant anomalous data. That is an important concern for me.
Whether the government filters information or whether a government agency filters information in an effort to “personalize your experience,” information consumers may lose the ability and the will to think critically. In terms of business research or competitive intelligence research, working around information gaps and public relations filters is difficult and time-consuming work.
As systems evolve, I often think of a quote by industrial designer Raymond Loewy that I find fascinating: “The main goal is not to complicate the already difficult life of the consumer.” It may be that filtering and narrowing one’s information perspective is an imperative in personalization and recommendations. I have no answer to the question, “What is lost when software automatically presents information the user wants?” |